Prosess og rådgivning / 6 minutter /
Ansvarlig KI er hele organisasjonen sitt ansvar!
Mange snakker nå om å bli mer datadrevet og dermed mer innovative. En organisasjon som skal bli god på datadrevet innovasjon må klare å løfte seg som organisasjon gjennom kundefokus (sluttbrukerfokus) og at man får tak i og kan bruke de dataene som skal til for å forstå kunden. For å få til det må store deler av organisasjonen kanskje endre seg. Vi forklarer her hvordan vi tenker at det bør og kan skje.



De dataene som brukes til å gi innsikt involverer ofte kunstig intelligens (KI). I dette arbeidet er data scientisten og data engineeren sentrale fordi de sørger for at data blir tilgjengelig og analysert.
Både fagfeltet, teknologien og det regulatoriske innen KI er i en rivende utvikling. Derfor er det krevende å ta de riktige avgjørelsene. Innen det teknologiske har det kommet mange gode verktøy, så modellering og regnekraft er ikke alltid den største utfordringen lenger. I Kantega har vi sett at det ofte er andre aspekter rundt utvikling av KI som smerter mest.
Ansvarlig KI
Vi som har KI som vårt fagfelt i Kantega har de siste årene jobbet mye med temaet ansvarlig KI. Vi ønsker at oppdragene og prosjektene vi jobber i skal utføres på en måte som gir en trygghet og tillit i resten av organisasjonen. Det skal være åpenhet og transparens i det vi gjør.
I denne artikkelen ønsker vi derfor å trekke fram sentrale elementer for å sikre at vi lager ansvarlig KI.
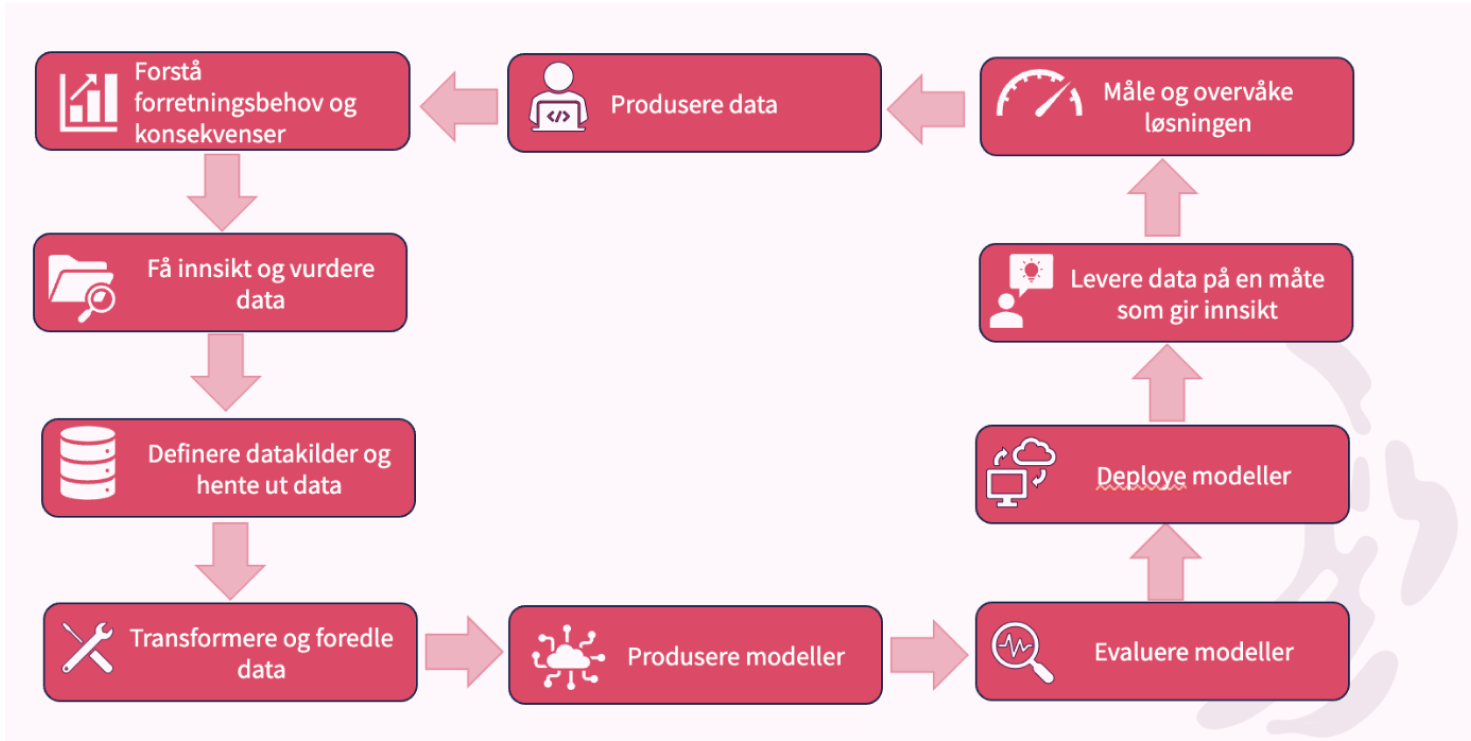
Figuren over viser en typisk syklus for et data science-prosjekt. Hvis vi ser på de ulike boksene, forstår vi at dette ikke er noe som kun berører data scientister, men derimot hele organisasjonen.
På samme måte som at et data science-prosjekt omfatter hele organisasjonen, er ansvarlig KI også noe hele organisasjonen har ansvaret for. I seksjonene under presenterer vi hvilke grep som bør gjøres i de ulike stadiene for å gjennomføre KI-prosjekter på en ansvarlig og trygg måte.
1. Produsere data
Data brukes og skapes i nesten alt arbeid vi gjør i en organisasjon. For eksempel trenger en saksbehandler data for å vurdere om en bruker skal få støtte eller ikke, og produserer data ved å lagre disse vurderingene. Når man skal finne ut om saksbehandleren kan få hjelp i dette arbeidet av kunstig intelligens, trenger man en forståelse av hva KI er og hvordan det eventuelt kan bli gjort enklere med enda høyere kvalitet.
Spørsmål vi bør ha svar på:
- Har vi kunnskap om hva KI kan brukes til?
- Har vi oversikt over hvilke begrensninger som finnes?
2. Forstå forretningsbehov og konsekvenser
Ingen KI-modeller er perfekte, og selv med mange iterasjoner og finjusteringer vil den gi feil prediksjoner. Som et ledd i ansvarlig KI er det derfor viktig å forstå hva forretningsbehovet er og hvilke konsekvenser det har både for bedriften og for brukerne. Et eksempel på dette er at terskelen for feil bør være vesentlig høyere ved en svindelprediksjon enn ved for eksempel epost-utsendelse i forbindelse med en markedskampanje. Begge deler kan gjøres med hjelp av KI, men konsekvensen ved feil er vesentlig alvorligere ved en svindelprediksjon. Vi må også gjøre en vurdering av hva som skal gjøres og hvor omfattende det er for organisasjonen å håndtere situasjoner der feil oppstår. Vi kan med andre ord stille oss spørsmålet: «Tåler dette prosjektet et negativt oppslag i en riksavis, og hvor stort omdømmetap vil vi som organisasjon få av dette?»
Spørsmål vi bør ha svar på:
- Er det greit at systemet av og til tar feil?
- Hvordan håndtere situasjoner der feil oppstår?
Tåler dette prosjektet et negativt oppslag i en riksavis, og hvor stort omdømmetap vil vi som organisasjon få av dette?
3. Innsikt og vurdering av data
På samme måte som vi bruker og produserer data i hele organisasjonen, er innsikt og vurdering av data et punkt som også må gjøres av hele organisasjonen. Som data scientist har du god kunnskap om muligheter og begrensninger ved de ulike modeller. Men du har ikke mulighet til å sitte med all dybdekunnskap for produkter og data. I en situasjon hvor vi for eksempel skal bruke KI for å lage salgsmodeller, vil vi trenge innspill fra salg for å forstå hvilken informasjon og mekanismer som brukes i kontakt med kunder. Det vil også være behov for innspill fra en produktansvarlig for å vite om produktet har endret vesentlig karakter, noe som vil påvirke hvor langt tilbake i tid vi kan bruke inputdata til modellen.
Er det persondata som skal benyttes er det også svært viktig å tenke på GDPR. Har brukeren gitt samtykke til at vi kan lagre data? Er formålet vårt forenelig med det vi har sagt til brukeren at vi skal benytte persondataen til?
Et siste, men viktig element i ansvarlighet: Selv om man har data det er lov å bruke og det er sterke indikasjoner på at det kan gi god prediksjonskraft, bør man bruke det hvis det ikke er etisk riktig?
Spørsmål vi bør ha svar på:
- Hva inneholder dataene?
- Hva slags hensyn må vi ta når det gjelder personvern/GDPR?
- Er det etisk riktig av oss å bruke dataene?
4. Definere datakilder og hente ut data
Når vi har fått svar på spørsmålene nevnt over, har vi gjerne kommet til punktet hvor vi skal hente ut og samle data fra ulike kildesystemer. Selv om vi ikke har brukt data i en KI-modell enda, er det fortsatt bruk av personopplysninger.
Vi må derfor ha kontroll på hvor data skal samles og eventuelt lagres. Med sensitive data må vi være ekstra oppmerksom på hvor de lagres, slik at vi ikke får en datalekkasje. I tillegg må vi tenke på om det er et krav til anonymisering av data. Data bør heller ikke ligge lagret til evig tid et sted med mindre det er et lovkrav, så vi må ha sletterutiner på plass. Når det kommer til sletterutiner er det også et poeng at en person kan trekke tilbake et samtykke til bruk av persondata når som helst, så det må være mulig å kunne slette persondata på en enkel måte.
Spørsmål vi bør ha svar på:
- Hvor skal data samles og hvor lenge skal de lagres?
- Har vi anonymisert dataene tilstrekkelig?
- Er det mulig å slette data på en enkel måte?
5. Datatransformasjon og foredling
Når data er hentet ut, starter jobben med transformering og foredling. Dette er den mest tidkrevende jobben for en data scientist og enkelte påstår man bruker opp mot 80 % av tiden på å klargjøre data for modellering. Dette steget handler om å få så mye informasjon ut av datapunktene som mulig, og vi tester derfor ulike måter å gjøre disse transformasjonene på. Et kjent problem her er at man ikke har god nok kontroll på konsekvensene av disse transformasjonene som igjen kan føre til uforventet atferd i modellene man trener, eller innføring av bias man ikke hadde sett for seg. Det er derfor viktig å ha rutiner for versjonskontroll av datatransformeringen og datasettene slik at de opprinnelige datasettene kan gjenskapes. Eksempler på dette kan være å innføre skjevheter i datasettet som vil påvirke modellen i en negativ retning. For mer om dette temaet, les Noras bloggartikkel: Anta bias. Alltid.
Spørsmål vi bør ha svar på:
- Har vi versjonskontroll på transformerte data?
- Kan vi spore transformasjoner tilbake til rådata/kilden?
- Innfører vi bias i transformasjonen/utvalget av data?
6. Produsere modeller
Med tilgang til transformert og foredlet data kan vi endelig begynne å produsere modeller!
Selv om det i den senere tid har kommet nyttige verktøy som tester mange modeller for deg og gir deg svar på hvilke som gir best prediksjon, er fortsatt skreddersydd modellering etter vår mening det beste alternativet. For er det virkelig sånn at den mest treffsikre modellen er den beste å bruke? En kjent sak er at jo mer komplekse modeller man bruker, jo bedre treffsikkerhet vil man få. Men det kan også gå utover hvor enkelt det er å forklare hva som faktisk skjer i selve prediksjonen. Det vil i de fleste tilfeller være enklere å kunne forklare hvordan en modell har kommet frem til et svar hvis man bruker en logistisk regresjon, enn et dypt nevralt nettverk. Og her må vi gjøre egne vurderinger for å finne et gunstig punkt for treffsikkerhet og forklarbarhet i hvert eneste prosjekt. I tillegg er det viktig å ha versjonskontroll på modellene sine, slik at det er mulig å gå tilbake i tid for å kunne forklare hvorfor et utfall ble gitt, selv om det er en modell som ikke lenger er i bruk.
En annen ting som dessverre ofte blir oversett er bærekraft. Fagfeltet er i en rivende utvikling om dagen og vi ser at det kommer nye, gigantiske modeller som for eksempel GPT 4. Disse store modellene krever veldig mye maskinkraft for å trenes. Og maskinkraft = strømforbruk som igjen er sterkt korrelert med CO2-utslipp.
Spørsmål vi bør ha svar på:
- Har vi tatt hensyn til forklarbarhet i modellen?
- Kan vi gå tilbake i tid og rekonstruere hvorfor en person fikk den scoren hen fikk på et gitt tidspunkt?
- Har vi tatt hensyn til strømforbruk relatert til trening av store modeller?
7. Modellevaluering
Etter å ha produsert en modell er det naturlig at vi evaluerer hvor bra den treffer. Her er det vanlig å måle nøyaktigheten til modellen på et datasett som er helt nytt for modellen, kalt valideringsdata. Det er flere måter å måle nøyaktigheten på, og hva man bør bruke henger ofte sammen med kostnaden eller alvorlighetsgraden ved å bomme. Et eksempel på dette kan illustreres med en modell som beregner sannsynligheten for at kundene dine ønsker å kjøpe et spesifikt produkt. Hvis du ønsker å gjøre et salgsfremstøt ved å sende ut eposter til mulige interessenter er kostnaden for å bomme relativt lav. Da vil det være viktig å sørge for at du har en modell som har flest mulig interessenter med høy kjøpssannsynlighet (gjerne kalt true positives). Om det er mange falske positive, folk modellen tror vil kjøpe, men som i realiteten ikke vil, er ikke så farlig sett fra et økonomisk perspektiv her. Om du derimot bruker modellen for å optimalisere for at noen skal selge ved å oppsøke mulige kunder eller ringe dem, så vil kravet til presisjonen være vesentlig høyere, fordi et mislykket salg vil ha en høyere kostnad. I praksis betyr det at vi optimaliserer modellen slik at utvalget av interessenter med høy kjøpssannsynlighet er mindre, men mer treffsikkert enn i eksempelet med utsendelse av eposter.
Et viktig aspekt i ansvarlig KI er også rettferdighet og diskriminering. Selv om vi ikke tar med kjønn eller etnisitet som variabel i modellen kan også mønster i annen data indirekte skille mellom dette. Det finnes metoder som kan sjekke om vi indirekte diskriminerer, noe vi bør ha kontroll på når vi evaluerer en modell. Det betyr også at ledelsen kanskje må involveres for å diskutere hvor rettferdige vi skal satse på å være.
Spørsmål vi bør ha svar på:
- Har vi optimalisert på riktig metrikk?
- Har vi vurdert om modellen er like rettferdig for alle brukere?
8. Modelldeployment
Modellen er laget og evaluert. Den treffer bra, kan forklares og er rettferdig. Du er nå klar for å produksjonssette den og skape enda mer forretningsverdi for bedriften din!
Når modellen går fra å være et lokalt prosjekt til at den skal eksponeres for hele verden på nettet, må du tenke på sikkerhet. Hvis infrastrukturen ikke er trygg nok, vil det kunne lekke data. Datalekkasje er alvorlig med tanke på brudd av personvernet og jo mer sensitive data man har, jo større vil problemet være med tanke på omdømme. I tillegg er det viktig å tenke på sikring av selve modellen. Hvis du har en modell som for eksempel gjør svindeldeteksjon, kan du med ganske høy sikkerhet si at ondsinnede aktører ønsker å få tak i denne. Hvis de klarer dette vil modellen ikke lenger ha noen verdi og svindlerne kan også avsløre underliggende bedriftshemmeligheter noe som vil være høyst problematisk.
Spørsmål vi bør ha svar på:
- Er infrastrukturen som støtter modellen tilstrekkelig sikret slik at man ikke kan lekke data?
- Kan ondsinnede aktører få tilgang til modellen og underliggende hemmeligheter?
9. Levere innsikt på en forståelig måte
Etter at modellen er satt i produksjon vil det neste naturlige steget være at brukere begynner å ha interaksjoner med den. Da er det viktig å forstå om brukere klarer å skjønne budskapet til modellen på en tilfredsstillende måte. For å kunne levere innsikten på en forståelig måte er det naturlig å involvere UX-folk (de som jobber med brukeropplevelsen) i denne prosessen. Et godt eksempel på hvor forståelig innsikten er presentert, er et avslag på en kredittkortsøknad:
«Vi kan dessverre ikke innvilge søknaden.
Avslaget er basert på de opplysningene du har oppgitt i søknaden, og informasjon vi har innhentet fra kredittbyrå og tilgjengelige offentlige registre.
Ta kontakt med oss dersom du ønsker mer informasjon»
Versus:
«Vi kan dessverre ikke innvilge søknaden din om kredittkort.
Hovedårsaken til dette er en kombinasjon av at du er ung, samtidig som at inntekten din er ganske lav.»
I disse to eksemplene ser man hvordan et resultat kan presenteres. Begge to er et avslag, men tekst nummer to gir brukeren en bedre forståelse av hvorfor utfallet er negativt.
Et annet eksempel er en modell som flagger mistenkelige transaksjoner for manuell sjekk. Som nevnt tidligere, vil en modell av og til ta feil. Og siden det er en maskin som gir oss svaret, har vi mennesker en tendens til å stole mer på dette svaret. I dette eksempelet vil da et menneske sitte og lete etter feil, selv om det ikke finnes. Og konsekvensen av dette er at transaksjonen feilaktig blir satt som mistenkelig, med de konsekvenser det måtte ha. Det er derfor viktig å få frem til konsumentene av modellen at denne modellen også kan ta feil og at man ikke alltid må stole 100 % på utfallet. Måten man kan få frem dette budskapet på er å brukerteste ulike forslag på presentasjonen av resultatet og se på reaksjonsmønsteret til de som brukertester.
Spørsmål vi bør ha svar på:
- Er resultatene fra modellen presentert på en forståelig måte til brukeren av systemet?
- Kan brukeren bruke resultatet slik det blir presentert?
- Kan brukeren melde tilbake til noen hvis de opplever svaret som feil?
10. Måle og overvåke
Det siste leddet i en modellsyklus er måling og overvåking. Et viktig premiss for å faktisk skape forretningsverdi med bruk av KI er at brukere har tillit til modellen. For hvis de ikke stoler på modellen vil de heller ikke bruke den og da vil den heller ikke gi noe verdi. Snarere tvert imot. Vi må derfor ha på plass overvåkning av systemet som sier noe om hvor ofte og hvordan den brukes. I tillegg vil kundenes bruksmønster endre seg over tid og modellen vil derfor treffe dårligere på sikt. Den må derfor re-trenes med jevne mellomrom. En lettvint løsning er å automatisk oppdatere modellen med ferske data med et gitt tidsintervall (nattlig, ukentlig, månedlig), men hvis vi gjør dette kan det også være fare for at man re-trener modellen slik at den blir dårligere. Et godt tips her er å «låse» modellen som er i produksjon, noe som vil si at den ikke oppdateres med ferske data, og heller ha en skyggemodell som re-trenes kontinuerlig med nye data. Når vi ser at skyggemodellen treffer bedre enn den modellen som er i produksjon, låses skyggemodellen og settes i produksjon. Hvis vi gjør re-trening på denne måten, vil vi få bedre kontroll og vi vil unngå både usikkerhet i organisasjonen og sikre trygg KI ut mot kundene.
Spørsmål vi bør ha svar på:
- Har vi oversikt over brukermønster og tillit til modellen?
- Har vi tilstrekkelig oversikt over hvordan modellen treffer både med og uten oppdateringer?
For å sikre ansvarlig bruk av KI, er det nødvendig at hele organisasjonen tar ansvar. Dette omfatter de tekniske utfordringene som produksjon av data, håndtering av data, modellering, sikkerhet og evaluering av modeller. Men også det mer organisatoriske som å forstå forretningsbehov og konsekvenser, etiske spørsmål, bærekraft, personvern og GDPR.
For å sikre at dataene og modellene brukes på en ansvarlig og trygg måte kreves en forståelse av både teknologien og konsekvensene ved bruk av KI. Ved å følge de nevnte grepene som er presentert i denne artikkelen kan organisasjoner lykkes med datadrevet innovasjon og skape tillit og trygghet i sine KI-prosjekter.