Automated Documentation of Data Transformations in Medallion Architecture (Azure Databricks)
This blog post will guide you through building an automated system to generate documentation for silver tables in Azure Databricks, integrating with Git (Azure Repos) for version control and collaboration.


Maintaining up-to-date documentation for data platforms is crucial for developers, data managers, and some data consumers. This is especially important when data platforms are built using the ["medallion architecture"] due to the multiple data transformations across various layers.
The medallion architecture comprises bronze, silver, and gold data layers (in addition to raw data), between which data transformations occur. The majority of transformations typically take place between the silver and gold layers. In these layers, the transformations are often documented by the code itself, making additional documentation unnecessary. Additionally, there are usually few or no transformations between the raw data and the bronze layer, as the raw data is simply ingested, making documentation for this step unnecessary.
However, documenting the transformations between the bronze and silver layers is important, as they involve critical changes that impact the data consumed by end users. These transformations may include actions such as dropping or renaming columns. The process is usually consistent and structured across different tables, making it feasible to document the bronze-to-silver transformations in a clear and systematic manner.
The setup involves extracting relevant data from the silver transformation code, writing this data into metadata tables, composing readable documentation, and committing it to a central repository for easy access. The entire process is automated, minimizing development time and requiring little attention after deployment. Moreover, this flexible setup allows you to document almost any transformation or property, as well as any information stored within your data.
While I won’t provide a complete, replicable code example, I will instead focus on the underlying concept that can be implemented and adapted to your specific environment.
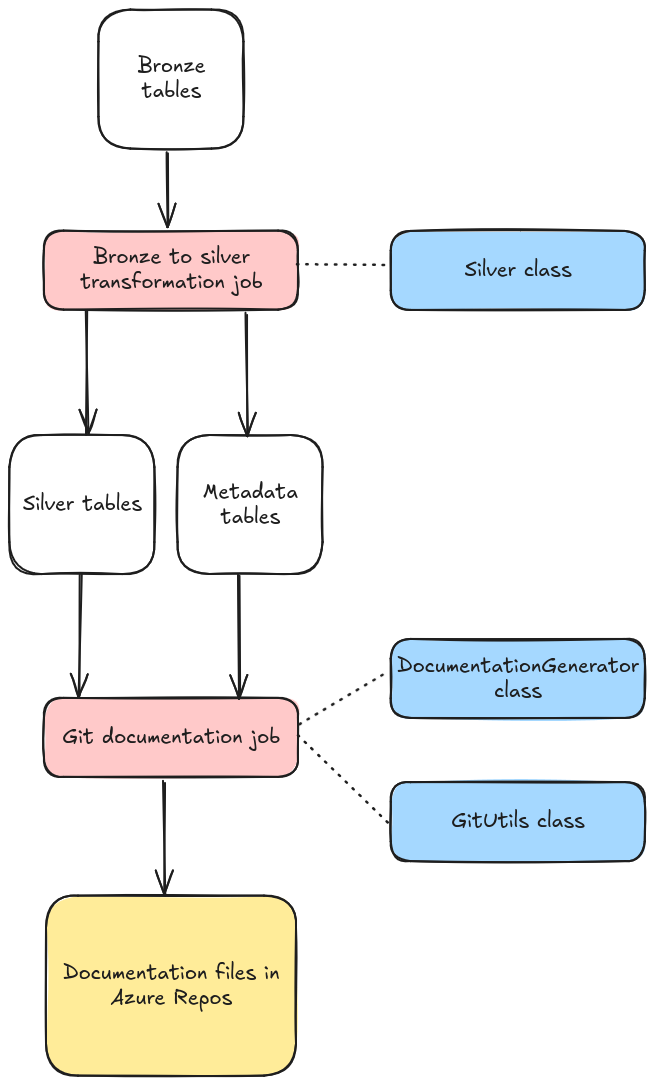

Figure above: the overall concept of the automated documentation system
Prerequisites
The automated documentation system requires the following tools and technologies:
- Azure Databricks Workspace
- Azure Repos
- Medallion Architecture
- Python and PySpark
- Ability to utilize `DefaultAzureCredential` for authentication to Azure Repos
How to? Step by step guide
Create Separate Metadata Tables During "Silvering"
Within the code responsible for silver transformations, include a method that generates separate metadata tables to document all bronze-to-silver transformations. Each silver table will now have a corresponding metadata table. I recommend storing these metadata tables in a separate schema with names that clearly correspond to their associated silver tables. This method can be invoked within your existing transformation code, ensuring it runs alongside the transformations, as shown in the example below.
1class Silver:
2 """Class that transforms Bronze tables into Silver tables."""
3
4 def __init__(
5 self,
6 silver_table_name: str,
7 bronze_table_name: str,
8 merge_column: str,
9 drop_columns: List[str],
10 rename_columns: Dict[str, str],
11 ): ...
12
13 ...
14
15 def _transform_bronze_to_silver(self, bronze_df: DataFrame) -> DataFrame: ...
16
17 def _write_silver_table(self, silver_df) -> None: ...
18
19 def _make_metadata_table(self) -> None:
20 """Create a metadata table for the Silver table."""
21 objects = [
22 "silver_table_name",
23 "bronze_table_name",
24 "drop_columns",
25 "rename_columns",
26 ]
27 values = [
28 self.silver_table_name,
29 self.bronze_table_name,
30 self.drop_columns,
31 self.rename_columns,
32 ]
33 data = [{"object": obj, "value": val} for obj, val in zip(objects, values)]
34 metadata_df = self.spark.createDataFrame(data)
35 metadata_df.write.mode("overwrite").saveAsTable(
36 f"{self.silver_table_name}_metadata"
37 )
38
39 def run(self):
40 """Transforms the Bronze table into the Silver table."""
41 ...
42 silver_df = self._transform_bronze_to_silver(bronze_df)
43 self._write_silver_table(silver_df)
44 self._make_metadata_table()
Extracting Information and Transforming it Into Strings
You need code that reads the information stored in the metadata tables and retrieves the table headers as strings. This will be invoked by an integration job responsible for pushing the documentation to a Git repository. I suggest that documentation files are written in Markdown format which is supported by Azure Repos. So, the code should also be able to convert the DataFrame’s header (or top rows) into a Markdown table, as illustrated in the example below.
1class DocumentationGenerator:
2 """Class that generates documentation for Silver tables."""
3
4 ...
5
6 def _convert_table_head_to_markdown(df: DataFrame) -> str:
7 """Converts the head of a DataFrame to a Markdown table."""
8 df = df.limit(5).sort(df.columns[0])
9 return df.toPandas().to_markdown(index=False)
10
11 def make_documentation_text(self, metadata_table_name: str) -> str:
12 """Create documentation string from a metadata table."""
13 metadata_df = spark.table(metadata_table_name)
14
15 silver_table_name = (
16 metadata_df.filter(col("objekt") == "silver_table_name")
17 .select("verdi")
18 .collect()[0][0]
19 )
20 bronze_table_name = (
21 metadata_df.filter(col("objekt") == "bronze_table_name")
22 .select("verdi")
23 .collect()[0][0]
24 )
25 drop_columns = (
26 metadata_df.filter(col("objekt") == "drop_columns")
27 .select("verdi")
28 .collect()[0][0]
29 )
30 rename_columns = (
31 metadata_df.filter(col("objekt") == "rename_columns")
32 .select("verdi")
33 .collect()[0][0]
34 )
35 silver_df = spark.table(silver_table_name)
36 silver_df_head_string = self._convert_table_head_to_markdown(silver_df)
37 silver_schema = silver_df._jdf.schema().treeString()
38 bronze_df = spark.table(bronze_table_name)
39 bronze_df_head_string = self._convert_table_head_to_markdown(bronze_df)
40 bronze_schema = bronze_df._jdf.schema().treeString()
41
42 documentation_string = [
43 f"# Transformation of table - {silver_table_name}\n\n",
44 "## Input\n\n",
45 f"### Bronze tabellnavn\n\n{bronze_table_name}\n\n",
46 "### Schema\n\n",
47 "```bash\n",
48 bronze_schema,
49 "\n```\n\n",
50 f"### Table head\n\n",
51 bronze_df_head_string,
52 "\n\n## Output\n\n" "### Schema\n\n",
53 f"### Silver tabellnavn\n\n{silver_table_name}\n\n",
54 "```bash\n",
55 silver_schema,
56 "\n```\n\n",
57 f"### Table head \n\n",
58 silver_df_head_string,
59 "\n\n",
60 "\n\n### Dropped columns\n\n",
61 f"`{drop_columns}`",
62 "\n\n### Renamed columnns\n\n",
63 f"`{rename_columns}`",
64 ]
65
66 return "".join(documentation_string)
67
68 ...
Integrating with Git
Additionally, you will need code for integrating with Git, which may require the most attention due to several considerations. At a minimum, the code should be able to:
- Create a new branch (e.g., based on "develop")
- Push documentation files to the new branch (I recommend one Markdown file per one table)
- Generate a pull request
You can also include additional features, such as:
- Assessing whether a significant change in the documentation file justifies creating a new version
- Checking if an unmerged pull request already exists in the system
1import requests
2
3
4class GitUtils:
5 """Utility functions for Git operations."""
6
7 def __init__(self, token, repo_settings, log):
8 """Initialize GitUtils object."""
9 self.token = token
10 self.repo_settings = repo_settings
11 self.log = log
12 self.headers = {
13 "Authorization": f"Bearer {self.token}",
14 "Content-Type": "application/json",
15 }
16
17 ...
18
19 def _if_file_exists_in_branch(): ...
20
21 def get_last_commit_id(): ...
22
23 def make_initial_commit(): ...
24
25 def simple_push(
26 self,
27 source_branch_name: str,
28 target_branch_name: str,
29 last_commit_id: str,
30 commit_comment: str,
31 file_path: str,
32 file_content: str,
33 ) -> None:
34 """Create a pull request and push to an existing branch."""
35 push_url = (
36 f"https://dev.azure.com/{self.repo_settings['organization']}/"
37 f"{self.repo_settings['project']}/_apis/git/repositories/"
38 f"{self.repo_settings['repository']}/pushes?api-version=7.1-preview.2"
39 )
40
41 if self._if_file_exists_in_branch(path=file_path, branch=target_branch_name):
42 file_change_type = "edit"
43 else:
44 file_change_type = "add"
45
46 data = {
47 "refUpdates": [
48 {
49 "name": f"refs/heads/{source_branch_name}",
50 "oldObjectId": last_commit_id,
51 }
52 ],
53 "commits": [
54 {
55 "comment": commit_comment,
56 "changes": [
57 {
58 "changeType": file_change_type,
59 "item": {"path": file_path},
60 "newContent": {
61 "content": file_content,
62 "contentType": "rawtext",
63 },
64 }
65 ],
66 }
67 ],
68 }
69
70 response = requests.post(
71 push_url,
72 headers=self.headers,
73 json=data,
74 )
75
76 if response.status_code == 201:
77 self.log.info(f"Push to {source_branch_name} made successfully.")
78 else:
79 raise ValueError(
80 f"Initial commit failed. Status code: {response.status_code}"
81 )
82
83 def create_pull_request(): ...
84
85 ...Databricks Git Documentation Job
The final step involves writing an integration job to automate the process of reading metadata information and pushing it to a new branch, along with creating a corresponding pull request using the code from the previous step. Once the job executes successfully, a new pull request should be ready for merging.
1from azure.identity import DefaultAzureCredential
2from DocumentationGenerator import make_documentation_text_from_metadata_table
3import GitUtils
4
5log = ... # Your logger
6
7repo_settings = {
8 "organization": "your_organization",
9 "project": "your_project",
10 "repository": "your_repository",
11}
12
13# Acquire a token using Managed Identity
14credential = DefaultAzureCredential()
15token = credential.get_token("{your-api-client-id}/.default").token
16headers = {
17 "Authorization": f"Bearer {token}",
18 "Content-Type": "application/json",
19}
20
21metadata_tables = ... # For example iterate over system tables
22
23# Initiate a Git object
24git = GitUtils(token=token, repo_settings=repo_settings, log=log)
25
26# Push a new documentation branch to remote (make initial commit)
27git.make_initial_commit()
28
29# Go through all metadata tables, generate documentation and push to the new branch
30for table in metadata_tables:
31 # Generate documentation string
32 doc_single_table = make_documentation_text_from_metadata_table(table)
33 # Make a push to the new documentation branch
34 git.simple_push(
35 source_branch_name="feature/documentation-silver",
36 target_branch_name="develop",
37 last_commit_id=git.get_last_commit_id(
38 target_branch="feature/documentation-silver"
39 ),
40 commit_comment=f"Made documentation for {table}",
41 file_path=f"/docs/Datatabricks-jobs/silver/{table}.md",
42 file_content=doc_single_table,
43 )
44
45# When done with all tables, create a pull request
46git.create_pull_request()Final Thoughts
There are few tools available for documenting bronze-to-silver transformations, and implementing them may not be straightforward in many environments. This is why a custom documentation system can be the easiest solution, providing exactly the information you need. Feel free to use this code for your development, and don't hesitate to reach out if you have any questions.