Teknologi / 10 minutter /
Avanserte maskinlærekonsepter: Federated Learning
I denne serien med artikler skal vi utforske forskjellige maskinlæremodeller, arkitekturer og konsepter som kanskje vil være nye for selv en med litt “Data Science”-erfaring.
Det forventes at leseren har en viss grunnleggende forståelse for maskinlæring og spesielt dyplæring, men har man ikke dette, kan det kanskje være litt spennende likevel ☺️
Github-link til kodeeksempelet i denne artikkelen finner du her.

Del 3: Federated Learning
I forrige artikkel utforsket vi Aktiv læring, en strategi for å redusere tiden man bruker på å merke (lable) umerket data før trening av en maskinlæremodell. I denne artikkelen skal vi se på en strategi der mange aktører kan trene en felles maskinlæremodell, uten å dele dataene sine med noen andre.
Hvorfor federated learning?
Når man skal trene en maskinlæremodell, er mengden og variasjonen i dataen svært viktig for hvor bra modellen blir. Som regel blir dataene innhentet fra eierne og overført til en sentral lokasjon der den blir brukt til trening. Dette medfører at eierne må gi fra seg dataene og stole på at den blir riktig ivaretatt.
Det er dessverre ikke sikkert at eierne har lyst eller lov å gi fra seg dataene, noe som kan medføre problemer for utviklingen i slike prosjekter.
Federated learning er et forsøk på å løse denne problematikken. I federated learning trenes modeller på dataeiernes data ute hos eierne, deretter overføres disse modellene til den sentrale lokasjonen der de kombineres til en global modell med kunnskap fra alle eierne.
Fordeler med federated læring er blant annet:
- Distribuert trening av maskinlæremodellen.
- Få trent en maskinlæremodell på data fra mange aktører uten at aktørene må gi fra seg dataene sine.
Hva er federated learning?
Federated learning er en strategi der vi i motsetning til å samle inn all data sentralt trener modeller lokalt hos data eierne forså å samle inn de trente modellene.
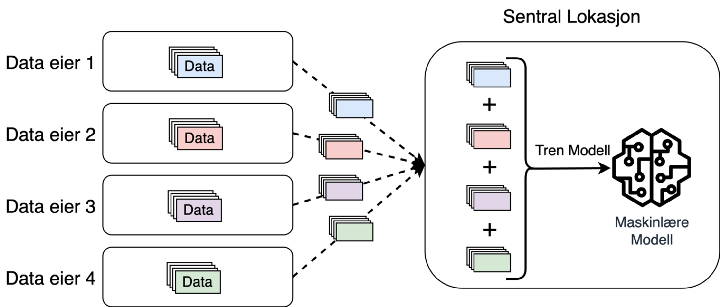

Typisk trening av maskinlæremodell, data blir innhentet fra dataeiere
Typisk trening av maskinlæremodell, data blir innhentet fra dataeiere
I figur 1 over kan man se en enkel illustrasjon av hvordan man typisk innhenter data fra dataeiere, aggregerer disse dataene i et datasett sentralt, og til slutt trener en maskinlæremodell på datasettet.
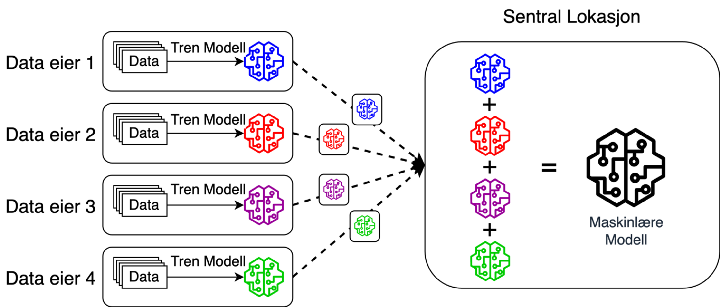

Figur 2: Federated Learning
Figur 2: Federated Learning
I figur 2 ser vi hvordan et federated learning oppsett kan se ut. Her ser vi fire dataeiere som selv trener en modell på dataene sine, deretter blir disse trente modellene sendt sentralt hvor de blir kombinert til en enkelt modell
Målet med federated learning er å dele kunnskapen til flere dataeiere med en sentral lokasjon, uten å måtte dele selve dataene.
I neste avsnitt skal vi igjen leke oss med MNIST-datasettet[1] gjennom et par eksperiment som forhåpentligvis kan fremheve styrkene ved federated learning.
Hvordan fungerer federated learning?
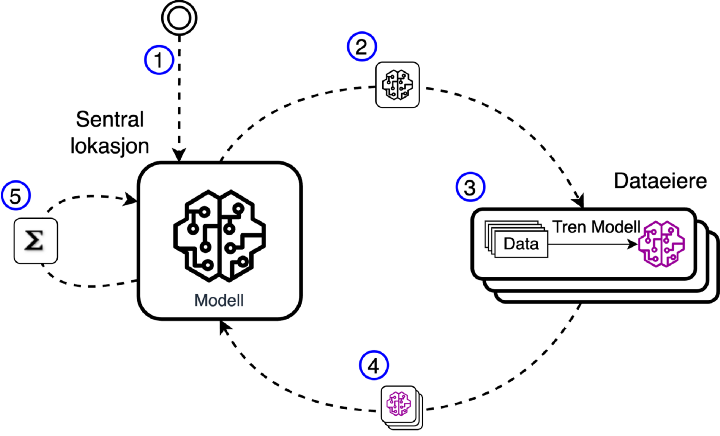

Figur 3: Federated Learning-syklusen
Figur 3: Federated Learning-syklusen
I figuren over ser vi en forenklet illustrasjon av stegene som inngår i federated learning-syklusen.
Steg 1: Opprettelse av global modell
I steg 1 oppretter vi en global modell hos den sentrale lokasjonen.
Steg 2: Overføring av modell til dataeiere
I steg 2 overføres en kopi av den globale modellen til alle dataeierne.
Steg 3: Trening av modeller hos dataeiere
I steg 3 trener hver enkelt dataeier maskinlæremodellen de mottok lokalt hos seg selv på sin egen data.
Steg 4: Overføring av trente modeller fra dataeiere
Når dataeierne er ferdige med treningen sendes de ferdigtrente modellene tilbake den sentrale lokasjonen.
Steg 5: Bygge global modell fra dataeiernes modeller
I Steg 5 kombineres modellene fra alle eierne til en ny global modell som erstatter modellen opprettet i steg 1. Kombineringen kan skje på forskjellige måter, men i vårt tilfelle lager vi den nye globale modellen ved å summere de vektede parameterene til alle dataeierene.
PS: Parameterne refererer her til vektene i det nevrale nettverket, og de blir vektet basert på hvor stor andel av de globale dataene den enkelte dataeier sitter på.
Etter at steg 5 er ferdig, starter syklusen en ny runde fra og med steg 2, der den nye globale modellen sendes til alle dataeierne og slik fortsetter syklusen til ønsket modellytelse er oppnådd.
Utrustet med en grunnleggende forståelse for prinsippet til federated learning skal vi nå bruke resten av artikkelen på et eksperiment der vi skal lage en simulering av federated learning på MNIST-datasettet.
Data


Figur 4: Utdrag fra MNIST, et datasett av håndskrevne tall
Figur 4: Utdrag fra MNIST, et datasett av håndskrevne tall
I eksperimentet vårt skal vi bruke MNIST-datasettet. Dette er et ferdig merket datasett bestående av 70 000 28x28 pixler store bilder av håndskrevne tall. I datasettet finner vi 10 klasser som representerer tallene fra 0 til 9.
For å simulere federated learning skal vi opprette 8 dataeiere og en sentral lokasjon. De 8 dataeierne eier deler av MNIST-datasettet mens den sentrale lokasjonen ikke eier noe data.
I et virkelig prosjekt vil dataene de forskjellige eierne eier variere, både når det gjelder hvor mye data hver eier har, men også hvilken type data de forskjellige eierne sitter på. For å illustrere dette skal vi utforske 3 scenarioer, der vi har fordelt MNIST-datasettet på 3 ulike måter.
Federated Learning Scenarioer
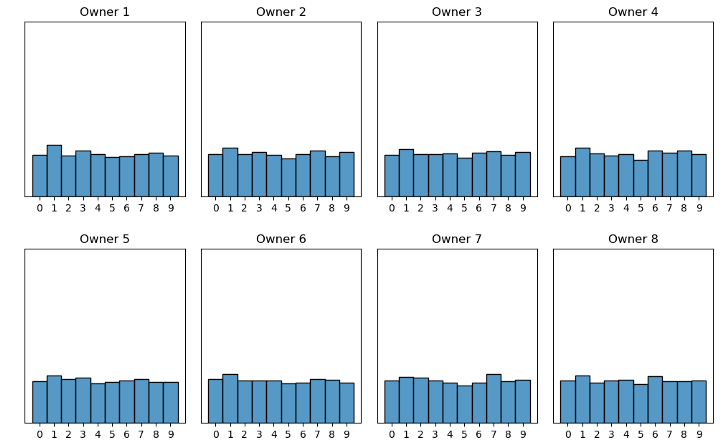

Figur 5: Scenario 1, alle eiere har like mye data
Figur 5: Scenario 1, alle eiere har like mye data
I scenario 1 eier hver dataeier like mye data, og datadistribusjonen er lik mellom eierne, se figur 5.

Figur 6: Scenario 2, eierne eier forskjellige mengder data
Figur 6: Scenario 2, eierne eier forskjellige mengder data
I figuren over ser vi en illustrasjon av hvordan dataene er distribuert i scenario 2. Til forskjell fra scenario 1 varierer det hvor mye data hver eier har. For eksempel så sitter eier 1 på mye mer data enn eier 6, 7 og 8.

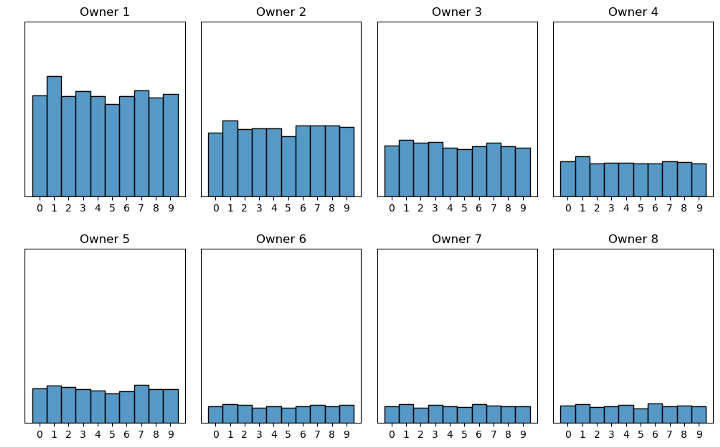
Figur 7: Scenario 3, alle eier like mye data, men har forskjellige mengder av de ulike bildene
Figur 7: Scenario 3, alle eier like mye data, men har forskjellige mengder av de ulike bildene
I det siste scenarioet, illustrert i figur 7, eier hver eier like mange bilder, men nå ulikt antall av de forskjellige bildene. For eksempel har eier 1 nesten ingen bilder av tallet null i motsetning til eier 8 som har veldig mange.
I løpet av de neste avsnittene skal vi utføre en simulering av federated learning på alle 3 scenarioene.
Kodeeksempel
Først skal vi se på hvordan koden ser ut for simuleringen vår.
Vi starter med å hente MNIST-datasettet, fordele labels og samples i hver sine arrays og normaliserer bildene til en verdi mellom 0 og 1. Deretter splitter vi dataene i trenings- og valideringssett med en fordeling på henholdsvis 70/30.
I kodesnippeten over ser vi hvordan vi oppretter 8 dataeierne. Først lager vi en klasse for å ta vare på data, labels og modellen til hver enkelt dataeier. Deretter deler vi opp all treningsdataen vår i 8 like store biter med å bruke “chunk_data”-funksjonen (hvordan denne fungerer kan man se her).
Til slutt bruker vi disse “databitene” til å opprette instanser av klassen Dataowner, og gir hver dataeier en midlertidig modell ved å bruke create_simple_model funksjonen (se kodesnippet under). Denne modellen vil senere bli erstattet av modellen laget i den sentrale lokasjonen.
I kodesnippeten over har vi selve federated learning-syklusen. Vi starter med å opprette en global modell (global_model).
Inne i selve syklusen henter vi ut vektene til den globale modellen og “overfører” disse til alle dataeierne, steg 2 i figur 3. Deretter trener vi dataeierne individuelt på sine egne data med funksjonen fit_model_to_data, vist under.
I det neste steget oppretter vi to tomme lister owner_weights, og scaling_factor_owners. I disse fyller vi opp vektene til dataeiernes modeller og scalingfaktoren til hver eier (skaleringsfaktoren er andelen av den globalen mengden data hver enkelt eier har).
Til slutt lager vi nye vekter for den globale modellen ved å summere vektene til hver eier multiplisert med deres skaleringsfaktor.
Resultater
Innledningsvis satt vi et mål om å teste ut federated learning på 3 scenarioer der dataene ble fordelt blant dataeierne på forskjellig vis. I den neste seksjonen skal vi se på resultatene for disse 3 scenarioene.
Scenario 1
Figur 8: Scenario 1, alle eiere har like mye data
Figur 8: Scenario 1, alle eiere har like mye data
I scenario 1 har alle dataeierne like mye data og jevnt antall bilder av de ulike håndskrevne tallene.
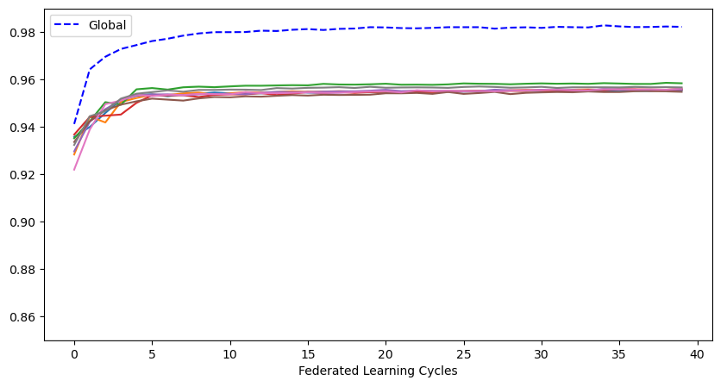

Figur 9: Scenario 1 resultater
Figur 9: Scenario 1 resultater
I figuren over ser vi 9 plott. Den stiplede linjen viser nøyaktigheten til den globale modellen trent gjennom federated learning. De 8 hel-fargede linjene viser nøyaktigheten hver enkelt dataeier hadde klart å oppnå hvis de hadde trent den samme modellen individuelt på sin egen data uten federated learning. Vi ser at nøyaktigheten til den globale modellen er på ca 98 % i motsetning til dataeiernes modeller på rundt 95 %.
Scenario 2
Figur 10: Scenario 2, eierne eier forskjellige mengder data
Figur 10: Scenario 2, eierne eier forskjellige mengder data
I scenario 2 har vi fordelt mengden data ulikt blant dataeierne, men innad hver dataeiers data er fordelingen ca. lik.

Figur 11: Scenario 3 resultater
Figur 11: Scenario 3 resultater
Som vi ser fra resultatene over, er det nå litt større variasjon i hvor bra dataeierne sine egne modeller gjør det. Vi ser igjen at den globale modellen er vesentlig bedre enn modellene dataeierne trente hver for seg.
Scenario 3
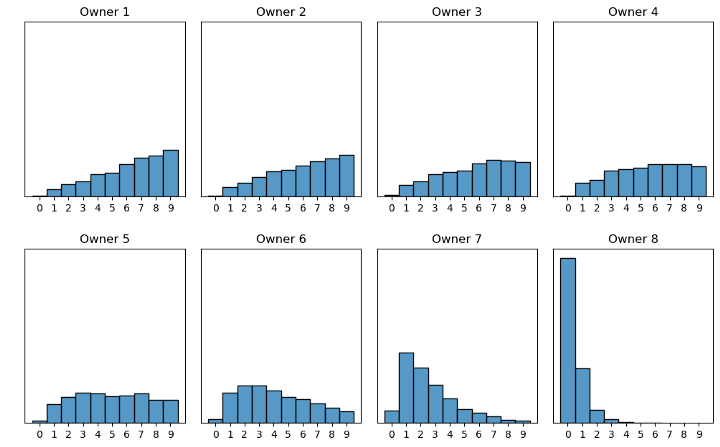
Figur 12: Scenario 3, alle eier like mye data, men har forskjellige mengder av de ulike bildene
Figur 12: Scenario 3, alle eier like mye data, men har forskjellige mengder av de ulike bildene
I scenario 3 har hver dataeier like mange bilder, men til forskjell fra de andre scenarioene sitter de på ulike mengder av de forskjellige bildene.
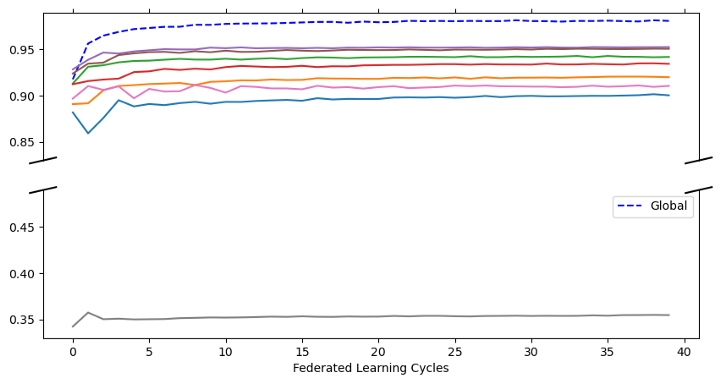

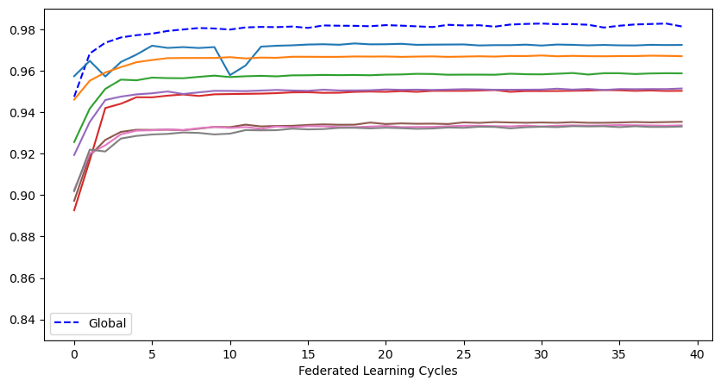
Figur 13: Scenario 3 resultater
Figur 13: Scenario 3 resultater
I figuren over ser vi at det nå er det større variasjon i hvor bra modellene til dataeierne har gjort det. Spesielt det nederste plottet (grå linje) viser at dataeier 8 kun har oppnådd en nøyaktighet på rundt 35 %. Men selv med stor variasjon i dataene til dataeierne ser vi at den globale modellen gjør det like bra som de globale modellene i scenario 1 og 2 med en nøyaktighet på ca. 98 %.
Dette betyr at selv om dataeierne gjør det dårlig individuelt sett, vil en felles global modell gjøre det veldig bra i alle scenarioer!
Confusion matrix scenario 3
I dette avsnittet skal vi ta en litt nærmere titt på scenario 3. Vi ser at dataeier 8 har svært dårlig modell nøyaktighet (ca. 35 %) dette fordi eieren hovedsakelig kun har data fra 3 av de 10 klassene.
Det vi skal undersøke nærmere er om selv denne dataeieren kan tilby noe positivt til fellesskapet.
For å utforske dette aspektet skal vi ta i bruk confusion matrix. Dette er en måte å visualisere resultatet til en modell etter at den har gjort en prediksjon på valideringsdatasettet. I matrisen ser vi antallet ganger modellen har predikert en klasse i kolonnene, og hvilken klasse de predikerte verdiene faktisk tilhører i radene. En perfekt modell vil kun ha verdier på diagonalen.
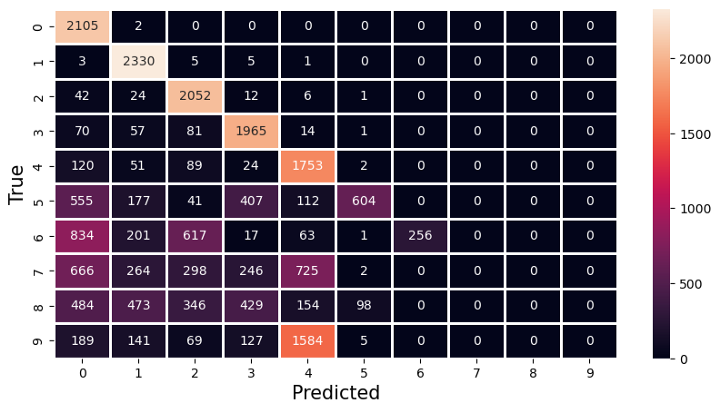

Figur 14: Confusion matrix scenario 3 dataeier 8
Figur 14: Confusion matrix scenario 3 dataeier 8
I confusion matrixen i figuren over ser vi resultatet til dataeier 8’s modell på valideringssettet. Vi ser at modellen er flink til å gjenkjenne tallene den har i datasettet sitt, men når det kommer til tallene 6–9 er den forferdelig dårlig. Dette gir mening siden dataeieren ikke har noen bilder av av disse tallene i datasettet sitt, se figur 12.
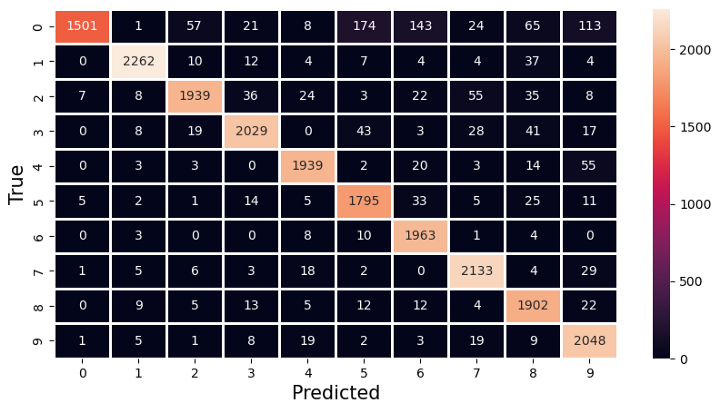

Figur 15: Confusion matrix scenario 3 dataeier 1
Figur 15: Confusion matrix scenario 3 dataeier 1
I figuren over ser vi confusion matrix for dataeier 1. Denne dataeieren har en modell med 95 % nøyaktighet, men som vi ser kommer den til kort når den skal predikere 0'ere (se rad 1, kolonne 1). Av 2107 har den korrekt klassifisert 1501.
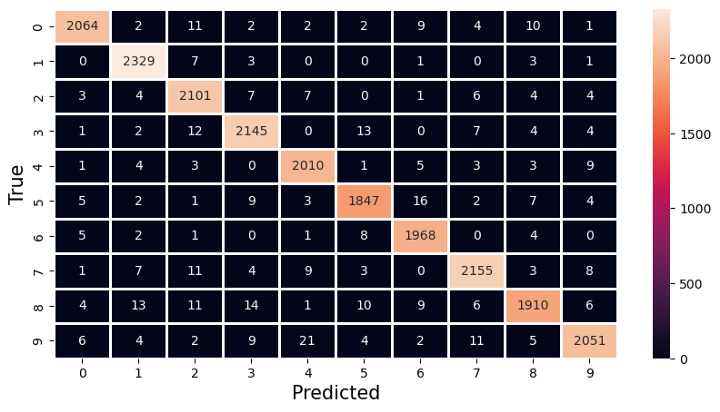

Figur 16: Confusion matrix scenario 3 global modell
Figur 16: Confusion matrix scenario 3 global modell
Til slutt ser vi confusion matrix for den globale modellen. Her ser vi at modellen jevnt over er god på å predikere alle tallene i valideringssettet.
Det vi kan lære av dette er at selv dataeier 8 som ikke har data til å trene en spesielt god modell, kan likevel være svært nyttig å ha med på laget i et federated learning oppsett.
Avslutningsvis kan vi konkludere med at federated learning kan være et svært nyttig redskap i tilfeller der vi ønsker å trene en maskinlæremodell på data fra flere dataeier, men hvor disse har ikke muligheten til å dele dataene sine med andre.
Potensielle forbedringer og videre arbeid
I denne artikkelen har vi kun fokusert på en måte å konstruere den globale modellen, nemlig gjennom en vektet summering av dataeiernes modeller. Det finnes flere måter å gjøre dette på som potensielt kunne forbedret ytelsen på den globale modellen.
Vi har også valgt å lage et DNN (Dense Neural Network) som modell for å klassifisere bilder. Dette er ikke den best egnede formen for maskinlæremodell for dette problemet og man vil nok fått andre resultater om man hadde f.eks brukt en CNN (Convolutional Neural Network). Om dette ville hatt en innvirkning på tidsforbruket er derimot usikkert, kanskje modellen hadde klart å oppnå en høyere nøyaktighet enda raskere enn den som ble laget i dette eksperimentet?
Avslutningsvis er det verdt å nevne at vi implementerte federated learning-algoritmen selv i denne artikkelen for å lære hvordan den fungerer. Heldigvis trenger man ikke å gjøre det på denne måten hver gang. I tensorflow-biblioteket er det innebygd støtte for å sette opp federated learning, noe som gjør prosessen vesentlig mye enklere.