Teknologi / 6 minutter /
Delta Lake – En moderne arkitektur for datalagring og analyse
Det er store gevinster ved å samle og foredle data på en god måte. Det er store gevinster ved å samle og foredle data på en god måte. Delta lake gjør det mulig å håndtere variasjon i innkommende data samtidig som vi sikrer kvaliteten og får et analysegrunnlag som vi kan stole på. I denne artikkelen vil vi vise hvordan dette kan settes opp.



Mange virksomheter har oppdaget gevinstene ved å flytte data ut i skyen. Tjenester som Amazon S3, Azure Data Lake og Google Cloud Storage, gir enorm skaleringsevne og stor fleksibilitet til en lav kostnad. Dette gjør det attraktivt å bruke skytjenester til å samle store mengder analysedata fra både interne siloer og eksterne kilder.
For å gi et analysemiljø gode arbeidsvilkår må du ha en god dataplattform i bunn. Du trenger en rask, oversiktlig og effektiv rigg for alle tilgjengelige data, uavhengig av datakildene. Datasettene bør oppdateres så snart nye data er tilgjengelig, og det bør være enkelt å hente inn nye kilder.
Ca 80% av tiden til en Data Scientist går med til datavask og preprosessering. Ved å tilgjengeliggjøre standardiserte datasett, uavhengig av kildene, får hele analysemiljøet mer tid til det som egentlig betyr noe; Å skaffe innsikt, bygge modeller og ta beslutninger basert på data man kan stole på.
I denne artikkelen vil vi introdusere Delta Lake og forklare hvordan arkitekturen legger til rette for å prosessere store datamengder med ulik struktur. Begrepet «Delta Lake» ligner veldig på «Data Lake», men er to forskjellige konsepter.
Med Data Lake mener vi filbasert lagring i skyen, mens Delta Lake både er et format og navnet på en arkitektur basert på dette formatet.
Vi vil også vise dataflyten gjennom Delta Lake-arkitekturen, og hvordan du håndterer versjonering, tidsaspekter, GDPR og datakvalitet – slik at du unngår å ende opp i en uoversiktlig datasump.
Delta Lake kan løse mange av de typiske problemstillingene knyttet til å sette sammen ulike kilder og foredle rådata for å frembringe innsikt med forretningsverdi. Analysearbeidet vil gå raskere, dataflyten blir mer transparent, og vedlikeholdsarbeidet vil reduseres betraktelig.


Delta Lake
Datasettene i en Data Lake lagres gjerne i Apache Parquet, oftest bare kalt Parquet. Parquet er et kolonnebasert filformat som lagrer strukturerte data på en langt mer effektiv måte enn radbaserte formater, som for eksempel CSV. Dette gjelder både filstørrelse og lese/skrive-hastighet. Parquet har bred støtte, kan håndteres både lokalt og hos alle de store skylagringsleverandørene, og egner seg godt for distribuert dataprosessering.
Delta Lake-formatet er et lag på toppen av Parquet, som tilrettelegger for effektiv og ryddig håndtering av data. Delta Lake gir støtte for ACID transaksjoner, hvor lagring av data enten skjer komplett og korrekt – eller feiler kontrollert og uten å korruptere videre dataflyt. Formatet gir også mulighet for “time travel” i datasettene, og det er støtte for fleksibel håndtering av schema.
Delta Lake er effektivt for spørringer mot ekstremt store datasett, fordi metadata om hver partisjon lagres sentralt, slik at du kun prosesserer relevante partisjoner basert på spørringen. Dette er gunstig, for eksempel ved sletting eller anonymisering av datasett.
Delta Lake ble opprinnelig utviklet av Databricks; et selskap som ble grunnlagt av folkene bak Apache Spark. Apache Spark er et industriledende rammeverk for distribuert prosessering av store datamengder. Det er motoren bak både dataprosesseringsverktøy og maskinlæringstjenester hos alle de store skyleverandørene. God støtte for kjente språk som Python, Scala, R og SQL gjør overgangen til distribuert prosessering mindre.
Dataflyt
I et Delta Lake-miljø bygger man opp en dataflyt der data lagres i flere nivåer, med økende grad av datakvalitet. Det er god praksis å benytte seg av 3 nivåer. Hvert hvert av nivåene bygger på hverandre, fra bronze til gold:
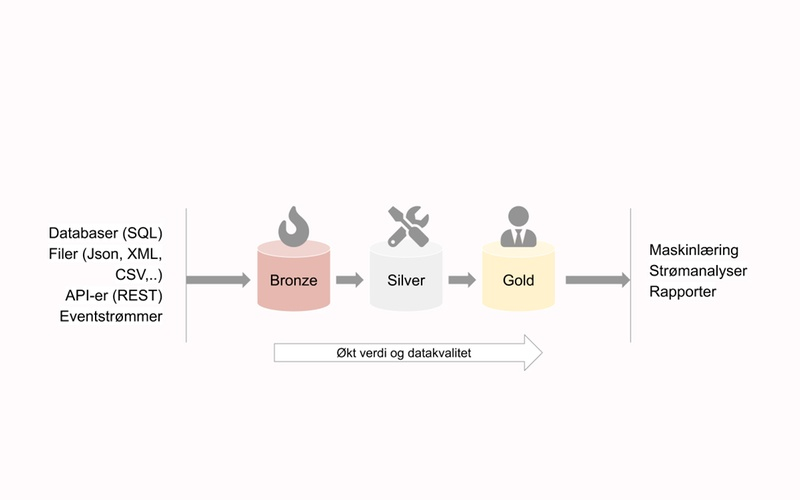

- Bronze: Her lagres inputdata rått som Delta Parquet. Alt lagres – uten å ta stilling til hva som er verdifullt eller nyttig. Ved å lagre uten transformasjoner, unngår vi informasjonstap knyttet til feil i preprossesseringslogikken. Ved å ta vare på rådata unngår vi å eliminere dataegenskaper som viser seg å få stor verdi på et senere tidspunkt. Typisk har data i Bronze lang, gjerne evig, oppbevaringstid.
- Silver: I dette mellomsteget lagres data der vi har gjort noe datavask og transformasjoner, med en standardisert struktur for alle datakilder. På denne måten unngår vi merarbeid utover Silver, hvis vi for eksempel endrer dataleverandør og format for en datatype. I Silver er det vanlig å slå sammen og berike ulike Bronze-datasett.
- Gold: Gold kan sees som serveringslaget. Gold-data er tilpasset for analyse for ulike forretningsområder. En Silvertabell kan generere mange Gold-tabeller, avhengig av bruksområde. Gold kan være et Delta Parquet-lag, men det kan også sees på som et abstrakt lag av ulike systemer, der en legger til rette for spesifikke bruksområder.
Ved å innføre et mellomsteg som Silver, tilrettelegger vi data som kan ha nytte og verdi for flere anvendelser i organisasjonen. Hovedjobben med å rense og standardisere datasettet gjøres kun én gang per datakilde, og vi unngår dermed unødvendig duplisering av både data og transformasjonskode.
Flyten, skissert over, sikrer datalinearitet. For hver endring i datasettene merkes transaksjonen med kilden som gir opphav til endringene. Vi kan dermed enkelt traversere gjennom lagene, og få oversikt over hvordan data har blitt transformert og endt opp i det formatet det er. Kombinert med god håndtering av metadata fra kilden, gir det et godt utgangspunkt for en analytiker som vil forstå hvilke data han eller hun egentlig jobber med.
Analytikeren kan også selv sette opp en flyt for å hente inn nye data. All logikk og kode for prosessering settes opp med versjonskontroll, og det åpnes opp for at flere kan foreslå endringer, transformasjoner, standarder og nye kilder. Dette er et stort og riktig steg bort fra datasettbestillinger i et adskilt datavarehus.
Støtte for både batch og strømprosessering
Data flyter mellom kvalitetsnivåene i en Delta Lake ved å implementere strømbaserte jobber som kontinuerlig oppdager og transformerer innkommende data. Spark Structured Streaming fungerer utmerket i kombinasjon med Delta Lake, fordi strømmeprosessen kun trenger å forholde seg til loggen for å detektere endringer – ikke innholdet i seg selv. Structured Streaming krever et Spark-cluster for å kjøre, som vanligvis faktureres per minutt clusteret kjører.
Strømprosesseringen kan optimalisere forholdet mellom dataprosesseringskostnader og hyppighet. I tilfeller der sanntidsaspektet er svært viktig, kan strømprosesseringsjobber transformere rådata opp gjennom Delta Lake-nivåene og produsere analyser med mikrosekunders forsinkelse.
Når folk tenker på prosessering av store datastrømmer assosieres det ofte med begreper som «sanntid», «24-7» og «kontinuerlig». Her er det verdt å påpeke at det finnes mange tilfeller der det holder at dataprosesseringen skjer én gang om dagen, kanskje fordi input-data leveres i batch, eller fordi maskinlæringsmodeller, analyser og rapporter kun behøver oppdatering med for eksempel daglige intervaller. I slike tilfeller er det unødvendig kostbart å holde et Spark-cluster kontinuerlig kjørende, og det kan være mer riktig å kjøre dataflyten som batch.
Ulempen med tradisjonell batch-prosessering er at vi da må ta stilling til hvilke filer som allerede er prosessert, hvilke jobber som feilet og hvilke data som må håndteres på nytt. Med Structured Streaming slipper vi å forholde oss til slike problemstillinger. Vi har fullt fokus på å trekke ut verdi fra dataene, mens rammeverket tar ansvar for datautveksling og feilhåndtering.
Det finnes en god løsning for å kjøre Structured Streaming som batch - med en trigger som kun fyrer av én gang, og prosesserer nyankomne data før jobben avsluttes. Jobben kan settes opp til å kjøre på de tidspunktene vi forventer nye data. På denne måten slipper vi å ha et cluster som kjører kontinuerlig. Om data på et senere tidspunkt ankommer hyppigere, er det bare én kodelinje som må endres for å endre fra batch/engangstrigger, til det vi vanligvis kaller strømming.
Delta Lake som lagringsmedium er også ideelt for eksplorativ dataanalyse. Her er det mange muligheter! Vi kan for eksempel benytte innebygde Spark-visualiseringer, dra nytte av Koalas (Pandas for Spark), eller konvertere til “kjente” datacontainere som Pandas eller R DataFrames, og jobbe videre med de bibliotekene en er mest komfortabel med.
Time travel
Delta Lake logger transaksjonene som genererer tabellene, og angir hvilke filer som er relevant på et hvilket som helst tidspunkt. Det gir mulighet for å gjøre såkalt “time travel” i datasettene. Syntaksen er selvforklarende:
`spark.read.option("timestampAsOf", "2021-01-01").load(<tabellens plassering>)`
Denne muligheten til å hente ut historiske øyeblikksbilder er uvurderlig i en analysesetting. Det gir et enkelt interface for å trene tidsindekserte data tilbake i tid, det er mulig å trene maskinlæringsmodeller basert på øyeblikksbilder av datasett, og det er støtte for å “rulle tilbake” til et tidligere tidspunkt, om en for eksempel har innført uønskede transformasjoner.


GDPR og sletting av data
Delta Lake er godt egnet til å håndtere GDPR-forespørsler, for eksempel “retten til å bli glemt”. Både sletting og anonymisering er godt dokumentert og kan kjøres svært effektivt, i motsetning til en tradisjonell Data Lake som i utgangspunktet bare er ment for å legge til nye data.
En kan sette opp jevnlige slettejobber, og den effektive måten Delta Lake benytter metadata på, gjør at en slipper en omfattende innlesning av hele datasettet. Det er også enkelt å scanne alt man har av tabeller som inneholder for eksempel en kunde-id, og slette eller anonymisere de relevante radene på alle lagringsnivå.
Validering av datakvalitet
Det finnes to paradigmer og ytterpunkter for lagring og håndtering av analysedata.
Tradisjonelle relasjonsdatabaser og datavarehus følger schema-on-write paradigmet. Før vi kan lagre data i slike løsninger må vi definere et skjema over hvilke tabeller og attributter vi skal ha. Når nye data skal lagres må disse først transformeres til gjeldende skjema. Dette gjøres ofte gjennom kjedede ETL (Extract, Transform and Load) operasjoner.
Forhåndsdefinerte skjemaer gir lite fleksibilitet, og vi får en utfordring når det kommer inn data som er verdifulle, men har en ny eller uventet struktur. Samtidig har vi også en stor fordel i at lagrede data er vasket og i henhold til påkrevd datakvalitet.
I stordata-løsninger, som data lakes, ser vi at det å løsrive seg fra skjemaer gjør det enklere å skalere til virkelig store datamengder og bygge inn fleksibilitet for fremtidige dataendringer. I data lakes lagres data rått og uten noen transformasjon. Vasking og transformasjon av dataene gjøres først ved utlesing og i overgangen til analyse. Denne tilnærmingen kalles schema-on-read. Fordelen her er at man unngår vi å kaste vekk dataegenskaper som senere viser seg å ha stor verdi.
En utfordring for schema-on-read tilnærmingen er at datakvalitet håndheves for sent, og man må ha mye fokus håndtering av feilsituasjoner i utlesingsoperasjonene. Det er også utfordrende å oppdatere eksisterende data, noe som gjør det krevende å håndheve retten til å bli slettet (GDPR) og anonymisere eller fikse feil i dataene i etterkant.
Med Delta Lake vil vi ha minimalt med transformasjoner for data som legges i Bronze. Men det kan være fornuftig å bestemme schema og å versjonere tabellene, dersom det oppstår schemaendringer i rådata. I overgangene til Silver og Gold vil vi i økende grad påkreve at data som flyttes over oppfyller satte kvalitetsvilkår. Samtidig gir mellomstegene gode muligheter for å sy sammen ulike versjoner slik at forbruksdata framstår ensartet.
Selv om Delta Lake gir stort handlingsrom for fleksibel håndtering av schema, er den fundamentale avveiningen mellom fleksibilitet og kontroll fortsatt gjeldende. Du bør implementere en god strategi for når og hvordan du vil luke ut feil og avvik i både datastruktur og datainnhold.
Ved å kjøre dataprossesseringspipelines i et fleksibelt Spark-miljø, for eksempel gjennom Databricks, er det mulig å implementere andre biblioteker for også å validere selve datainnholdet. Det er mange implementasjoner man kan vurdere, for eksempel Great Expectations, men det er også mulig å skrive skreddersydd kode som plukker opp problemer som angår spesifikke datakilder. Generelt er det en god idé å plukke opp problemer tidlig i en datapipeline, før dårlige data når ut til rapporter og modeller.
Jo mindre feil som populeres utover, jo mindre blir ryddejobben i etterkant.
Konklusjon
I følge Gartner, vil 85% av alle AI-prosjekter feile frem til 2022 . Vår påstand er at dette estimatet er sterkt korrelert med kvaliteten på dataplattformen som ligger til grunn for prosjektene. En robust og smidig dataarkitektur er grunnmuren i en god dataplattform.
Veien fra en visjon om en dataplattform til implementasjon kan virke omstendelig og lang, men det er ikke tilfelle. Alle de store skyleverandørene har gode og i stor grad ferdige løsninger for å hoste en arkitektur som foreslått over, både for innhenting, transformasjon og deling av data.


Det er store gevinster ved å samle og foredle data på en god måte. Analysearbeidet vil gå raskere, dataflyten blir mer transparent, og vedlikeholdsarbeidet vil reduseres betraktelig. Tiden det tar få inn nye datakilder vil kuttes drastisk, og flere kan bidra og få oversikt over hele dataflyten, fra rådata og frem til endelig modell og rapportering.
Ønsker du å komme i gang og få et solid grunnlag for datadrevet innsikt og operasjonell anvendelse av maskinlæring? Ta gjerne kontakt for å høre hvordan Kantega kan bidra med å sette opp en rask, skalerbar, smidig og robust dataplattform i ditt miljø.