Teknologi / 3 minutter /
Sommerprosjektet 2023 - Fremtidens chatbot (2023, Trondheim)
Hvordan kan man mest effektivt hente relevant informasjon til et brukerspørsmål? Hva kreves for å få en stor språkmodell til å svare på den måten man vil? Dette var noen av de mest sentrale spørsmålene vi har utforsket i løpet av vårt sommerprosjekt.


I seks uker har vi jobbet på et prosjekt for Enova SF, hvis hovedmål er å være den største bidragsyteren til Norges omstilling til et lavutslippssamfunn gjennom mer effektiv energibruk, økt fleksibilitet i energisystemet eller reduserte klimagassutslipp. For den enkelte bedrift eller privatperson kan det være kostbart og risikabelt å ta i bruk nye, klimavennlige teknologier. Teknologiene som støttes er tilgjengelige i markedet, men har ikke blitt tatt i bruk i stort omfang. Ved å bidra med økonomisk støtte skal Enova gi disse løsningene en ekstra dytt slik at de etableres i markedet.
I skrivende stund bruker Enova mye ressurser på kundestøtte, hvor mange av spørsmålene som kommer inn fra privatmarkedet kan finnes på Enovas nettside. For å få ned antall kundehenvendelser vedrørende slike svar, foreslo Enova å lage en chatbot basert på kunstig intelligens, slik at en bruker som ønsker å benytte seg av Enovas støttetiltak kan bli mer selvhjulpen. I dette blogginnlegget presenterer vi interessante funn ved implementasjon av den tekniske løsningen av chatboten.
En smart chatbot?
Det er ikke tvil om at chatboter tradisjonelt sett ikke er foretrukket når man skal finne informasjon. Likevel ser fremtiden lys ut for chatboter etter den kraftige fremveksten av store språkmodeller i løpet av det siste året, slik Nora diskuterte i et blogginnlegg tidligere i år (Ja, nå kan du ENDELIG skrote chatbotten din!). Muligheten til å kunne forstå og svare med naturlig språk, gjør at chatboter potensielt kan svare på en mye mer «menneskelig» måte enn tidligere. Samtidig åpner store språkmodeller for et bredere spekter av svar på grunn av mulighet for å resonnere, og er dermed ikke låst til et sett med pre-definerte svar.
Hypotesen på starten av prosjektet var dermed at vi kan brukeOpenAI sin store språkmodell GPT 3.5 til å kunne svare på brukerspørsmål. GPT-familien har blitt noen av de mest kjente og utbredte store språkmodellene i dag, og er trent på «hele» internett. I utgangspunktet burde da GPT kunne svare godt på data om Enova, men vi har et stort problem; modellene er trent på data fra 2021. Enova oppdaterer energitiltakene sine flere ganger i året, og vi har dermed behov for helt fersk data for å kunne svare godt.
For å kunne svare godt med oppdatert data, må vi på en eller annen måte «lære» en GPT-modell ny informasjon spesifikt om Enova. Tradisjonelt sett gjøres dette ved å finjustere (eng. «fine tune») modeller. GPT sin kildekode er ikke åpen for allmenheten, så finjustering av selve modellen er ikke et alternativ. Vi måtte dermed ty til en relativt ny prosess som kalles «grounding». I korte trekk består grounding av at man «manuelt» legger ved relevant data ved hvert enkelt spørsmål til en stor språkmodell.
Smartere søk
Grounding-prosessen foregår i hovedsak i to steg: når vi henter og gjør klar data for å søkes i, og når vi faktisk generer svaret fra chatboten.
Dataen som ligger til grunne for å holde chatboten oppdatert er hentet direkte fra Enova sine nettsider ved typisk scraping. GPT-modellen kan kun ta inn et visst antall «tokens» (1 token = ca. ¾ av et ord) av gangen, så for å holde lengden på hver input under maks-grensen er innholdet fra nettsiden videre delt opp i mindre biter.
Hver enkelt bit av innhold brukes til å generere en embedding – en vektor med flyttall som kan sees på som en stor språkmodell sin interne representasjon: rett og slett språkmodellens idé eller tanke om et konsept. Hver slik vektor-embedding legger vi så i en egen database, slik at de kan gjenbrukes frem til en eventuell endring på Enovas nettsider. For vårt bruk er vektor-embeddings svært nyttig, da det er bevist at vektorene til relaterte konsepter (eller rett og slett biter med tekst) vil være nært hverandre i vektorrommet. Ved relativt enkel matematikk som Pytagoras læresetning eller cosine similarity kan man dermed finne ut hvorvidt to tekster, som ikke nødvendigvis er like ord for ord, er konseptuelt like.
Ved spørsmål til chatboten kan vi dermed generere en vektor-embedding til selve spørsmålet i sanntid, som vi sammenligner med vektorene i databasen for å hente de mest relevante bitene med informasjon. Ved å legge informasjonen med i spørsmålet til GPT, klarer den å svare på spesifikke spørsmål om Enova med naturlig språk.
Utfordringer med store språkmodeller
Resultatene våre viser at chatboten generelt svarer bedre enn en tradisjonelt «dum» chatbot, men vi har også møtt på noen utfordringer rundt det å bruke store språkmodeller. GPT sin kildekode er som nevnt ikke åpent for allmenheten, så selv om vi vet hvordan den fungerer i store trekk kunne den like gjerne vært en sort boks. Spesielt ettersom all input baserer seg på naturlig språk, har det vært vanskelig å forutse hvordan endringer i input utgjør endringer i output. I kombinasjon med at GPT 3.5 i utgangspunktet ikke er så styrbar (eng. «steerable») har dette medført mye prøving og feiling for å lage god input som kan mates inn i modellen. Midtveis i prosjektet byttet vi fra en fullstendig manuell flyt til rammeverket LangChain, som har gjort resultatene våre noe bedre. Vi skal nå likevel ta for oss et par forbedringer som vi har eksperimentert (og fortsatt eksperimenterer) med.
Hypotetiske svar ble først beskrevet i en forskningsartikkel fra 2022, «Precise Zero-Shot Dense Retrieval without Relevance Labels» (Gao, Ma, Lin, Callan). Artikkelen beskriver en flyt hvor man sammenligner vektor-embeddingene i informasjonsdatabasen med et hypotetisk, eller falskt, svar som er generert av en GPT-modell. Hypotesen er at et slikt svar vil være konseptuelt likere informasjonen som ligger i databasen, ettersom den sannsynligvis inneholder utsagn og ikke spørsmål. I den manuelle flyten vi hadde før LangChain var dette ferdig implementert (med veldig gode resultater), men da LangChain allerede har en viss form for lignende funksjonalitet avventer vi med å legge det til i endelig versjon.
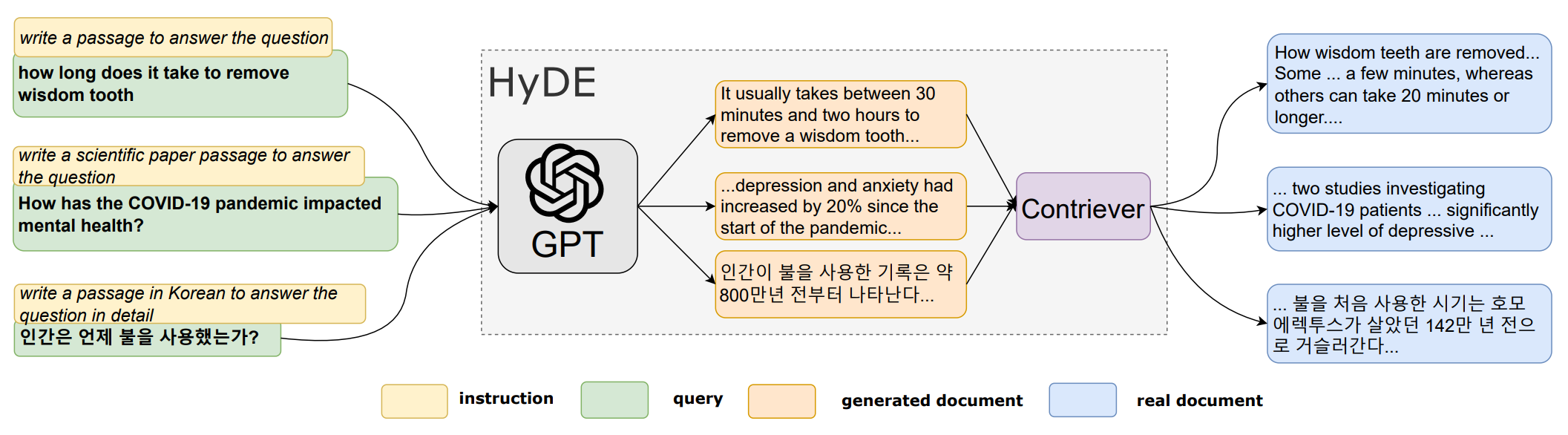
Illustrasjon av HyDE-modellen som våre hypotetiske svar er basert på (Gao, Ma, Lin, Callan)
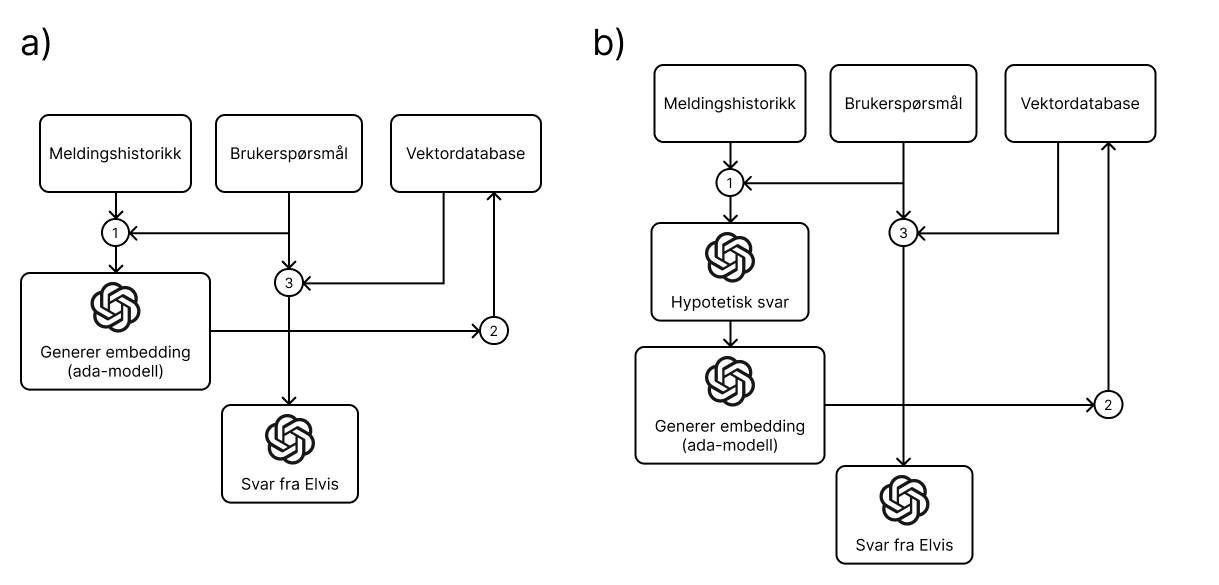
Visualisering av normal flyt (a) og flyt med hypotetisk svar (b)
Oversetting av input og output baserer seg på vår hypotese om at en stor språkmodell som GPT presterer bedre på engelsk enn på andre språk, da mesteparten av internett (som den er trent på) er på engelsk. Vi har derfor eksperimentert med en flyt hvor alt foregår på engelsk, hvorav input først oversettes til engelsk og output til slutt oversettes tilbake til norsk. Dette medfører flere kall til GPT (og dermed ekstra forsinkelse i svar), og vi har per dags dato bestemt at dette må optimaliseres ytterligere før det kan bli med i den endelige løsningen.
Chatboten gjennom prosjektet
Avslutningsvis presenterer vi et spørsmål fra bruker og tilhørende svar fra chatboten som oppsummerer endringene vi har gjort i løpet av prosessen. Hvert av svarene besvarer spørsmålet "Hvor mye kan jeg få i støtte for å installere solceller?".
Før embeddings
1Det er avhengig av størrelsen på anlegget og hvor mye energi det vil produsere, samt andre faktorer. Enova tilbyr en støtteordning for solceller hvor du kan få inntil 28% av investeringskostnadene dekket. Du kan finne mer informasjon og søke om støtte på Enovas nettside.Første fungerende versjon
1Du kan få inntil 47 500 kroner i støtte når du begynner å produsere din egen elektrisitet gjennom solcelleanlegg. Enova justerer tilbudet i Enovatilskuddet høsten 2023.
2
3Enova reduserer støtten til solcelleanlegg fra 1. oktober 2023. Støtten endres fra 2.000 kroner per kW installert til 1.250 kroner. Satsen på 7.500 for et produksjonsanlegg vil opprettholdes.
4
5For å få dagens støttesats må tiltaket både være ferdigstilt og registrert med faktura i Enovas søknadsportal innen 30. september 2023. Mer informasjon finner du på Enovas nettside.Med hypotetiske svar
1Du kan få opptil 47 500 kroner i støtte når du installerer et solcelleanlegg i din helårsbolig eller fritidsbolig i Norge.
2
3Støtten endres fra 2 000 kroner per kW installert til 1 250 kroner fra 1. oktober 2023. For å få dagens støttesats må tiltaket både være ferdigstilt og registrert med faktura i Enovas søknadsportal innen 30. september 2023.
4
5Støtten gjelder kun for nyetablerte anlegg og ikke for utvidelse av eksisterende anlegg.Med svaret vi her fikk fra chatboten ser vi ikke markante endringer fra forrige versjon, men det har vist seg at den bedre håndterer kontekst fra tidligere meldingshistorikk mm.
Introduksjon av LangChain og flere finjusteringer
1Du kan få inntil 47 500 kroner i støtte fra Enova når du begynner å produsere din egen elektrisitet med solcelleanlegg. Støtten vil reduseres fra 1. oktober 2023 fra 2.000 kroner per kW installert til 1.250 kroner.
2
3For å få dagens støttesats må tiltaket både være ferdigstilt og registrert med faktura i Enovas søknadsportal innen 30. september 2023. Dokumentasjon av kostnader må være i samsvar med norske lover og forskrifter, og installasjonen må være utført av et registrert firma.
4
5Resten av støtten avhenger av hvor stor kapasitet anlegget har. Installerer du et solcelleanlegg kan du få 7.500 kroner i støtte, i tillegg til 2.000 kroner per kWp installert effekt, opptil 20 kW. Totalt kan du få inntil 47 500 kroner.
6
7For mer informasjon, kan du besøke [Enova.no](https://www.enova.no/privat/alle-energitiltak/solenergi/solcelleanlegg/).Veien videre
Chatboten vi har utviklet i løpet av de seks ukene i sommerprosjektet har virkelig prestert bedre enn vi originalt hadde trodd, men som nevnt har vi også hatt utfordringer med å få svar på det formatet vi ønsker. Så hva kan gjøres videre for å forbedre chatboten? Vi kan avsløre at i løpet av prosessen har vi også hatt tilgang til en privat versjon av GPT-4 som vi har testet parallelt, ettersom Enova fortsatt er på venteliste for tilgang. Spoiler alert: GPT-4 fikser de aller fleste problemene våre, uten videre utvikling. Om dette er veldig kult eller veldig frustrerende, er opp til tolkning 🥲





