Teknologi / 8 minutter /
MLOps i praksis: Full kontroll fra første eksperiment til produksjonspipelines
Med godt strukturerte og sporbare data i bunn, ligger mye til rette for å håndtere maskinlæring på en god måte. Neste steg på veien, er et miljø for å utforske data, skrive datapipelines, bygge modeller og gjøre modellene tilgjengelig for anvendelse.


Vi har tidligere beskrevet en ideell dataflyt for effektiv lagring og håndtering av store datamengder for analyse. I denne artikkelen vil vi forklare hvilke elementer som er viktig når man setter opp et skybasert analysemiljø. Vi begynner med en beskrivelse av nåsituasjonen, og hvor langt man typisk har kommet med strukturering og systematisering av ML-utvikling. Vi vil deretter gjennomgå hvilke krav man bør sette til infrastrukturen man tar i bruk. Til sist vil vi gi et praktisk løsningsforslag.
ML-systemer i dag
Maskinlæring blir stadig mer utbredt og aktuelt. Mengden data vokser eksponentielt samtidig som maskinvaren blir kraftigere, og gjør det nyttig å ta i bruk det som egentlig ofte er gamle statistiske modeller, men som tidligere har vært umulig å dra nytte av for store datamengder. Med dette har utviklingen av biblioteker og rammeverk som gjør det enklere å bruke maskinlæring eksplodert i popularitet, og med tiden også modnet.
Men selve ML-koden som trener modeller er i virkeligheten bare en liten del av ML-systemer. Dessverre, vil mange gjerne si, fordi det er dette man gjerne tenker er det mest spennende. En stadig bedre modell, som med mer data lærer stadig mer og optimaliserer prosesser - som å foreslå hvilken TV-serie du bør sjekke ut. Men hva med alt rundt?
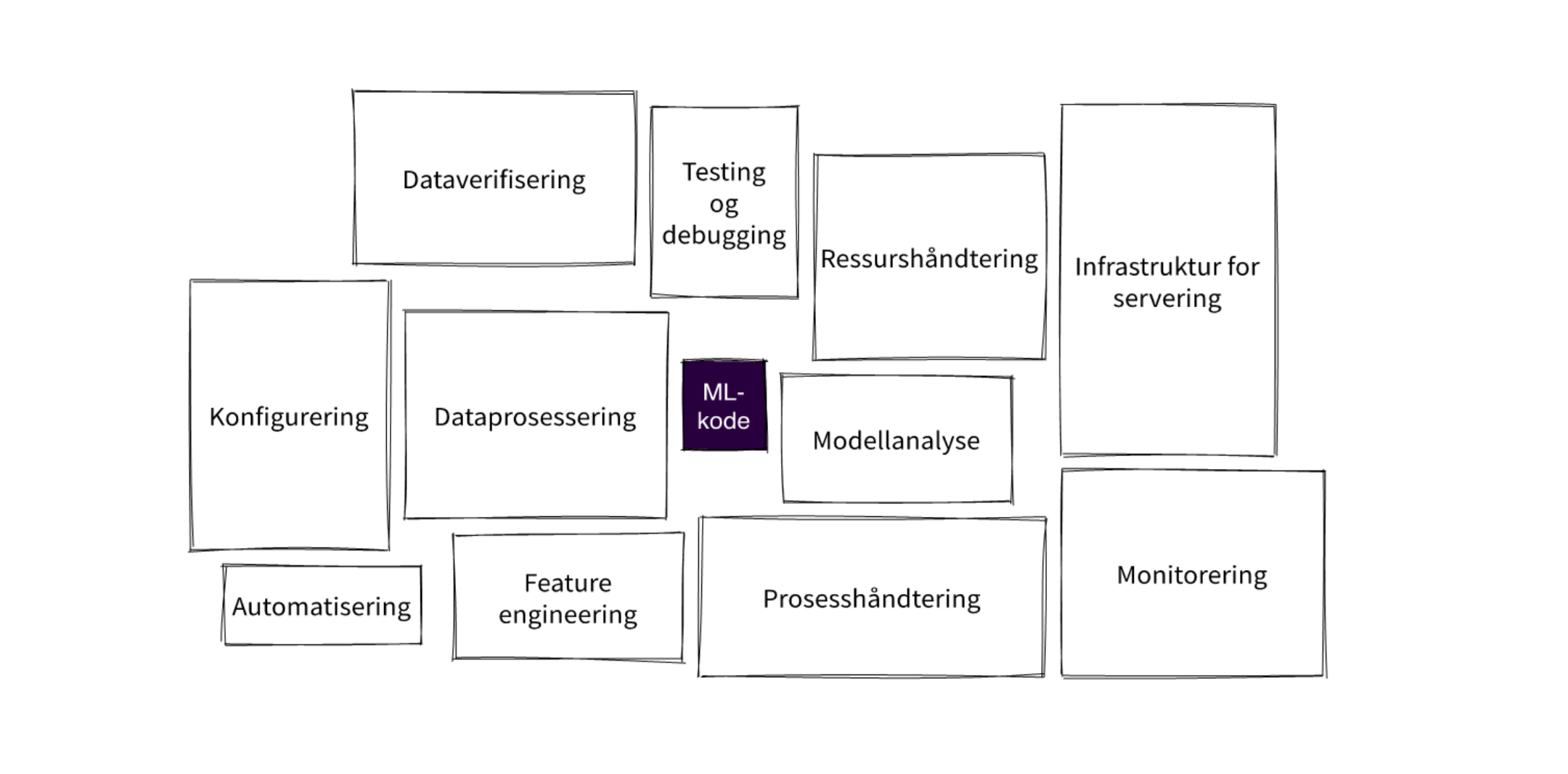

Figuren over er basert på artikkelen «Hidden Techincal Dept in Machine Learning Systems», og viser landskapet man egentlig opererer i når man setter opp et system for maskinlæring. Det er altså mer enn enn Tensorflow eller Scikit-learn som må på plass for et produksjonsklart og skalerbart økosystem for maskinlæring.
MLOps, som kort fortalt er DevOps for maskinlæring, tar for seg mye av det vi ser i figuren. Selv om noen vil påstå at MLOps bare er en fancy wrapping rundt et etter hvert modent begrep, finnes det et par fundamentale forskjeller mellom DevOps og MLOps.
Den største utfordringen innen utvikling for maskinlæring er dataavhengighet. Der en vanligvis kan lete seg tilbake i kodehistorikken for å spore endringer i kode, er det umulig for trente maskinlæringsmodeller. Koden som definerer måten disse trener på er nærmest verdiløst for reproduserbarhet uten de data som tok del i modelltreningen.
En annen utfordring er kompetanse. Typiske ML-team består gjerne av data scientister som aldri har vært borti programvareutvikling. Det er for eksempel ikke uvanlig at data scientistene jobber med sin egen kode og leverer et sluttprodukt, uten noen form for peer review.
Vår erfaring tilsier at mange virksomheter som setter i gang ML-prosjekter mangler en helhetlig tankegang rundt infrastruktur og MLOps. Prosjektene, som alt for ofte merkes som en POC, begrenses gjerne til å hente datasett som kan brukes for å trene en modell, datapreprosessering og modelltrening, og til slutt en metode for å bruke modellen som krever minst mulig ny infrastruktur. For eksempel gjennom et script i et datavarehus som jevnlig gir kunder en score basert på en forhåndstrent modell.
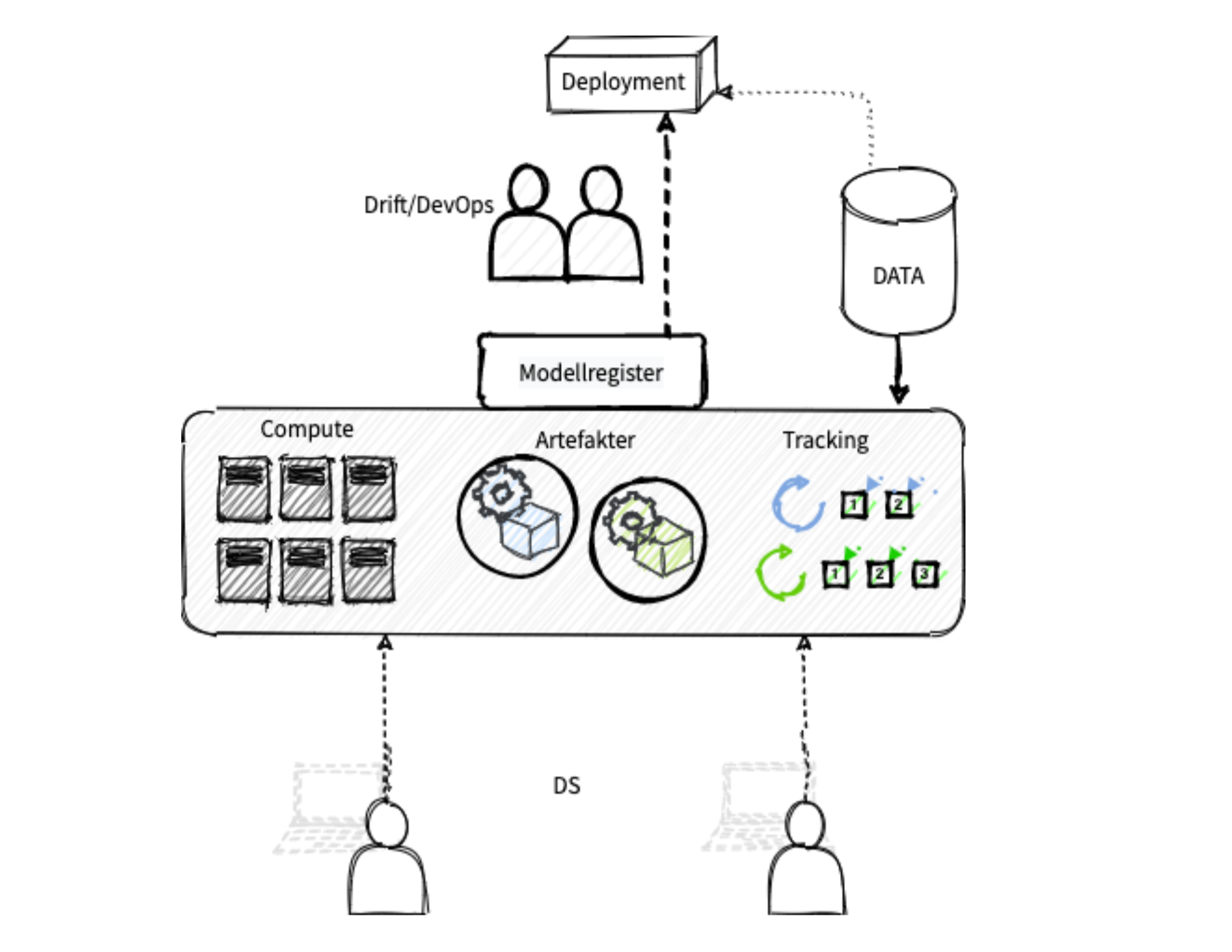
Bildet under demonstrerer en situasjon av denne typen. Data scientister (DS), henter data ad hoc til egen maskin, setter opp en datapipeline og trener en modell. Selve ML-koden håndteres gjerne med et versjonskontrollsystem, men modellobjektene og data som brukes til trening blir i beste fall kun implisitt beskrevet gjennom signatur og aggregerte statistikker.
Utviklingen skjer lokalt på DS-teamets egne maskiner. Det blir raskt rot og merarbeid på grunn av ulike biblioteker og versjoner av biblioteker, og en må stadig synkronisere lokale miljøer på tvers av DS-teamet.
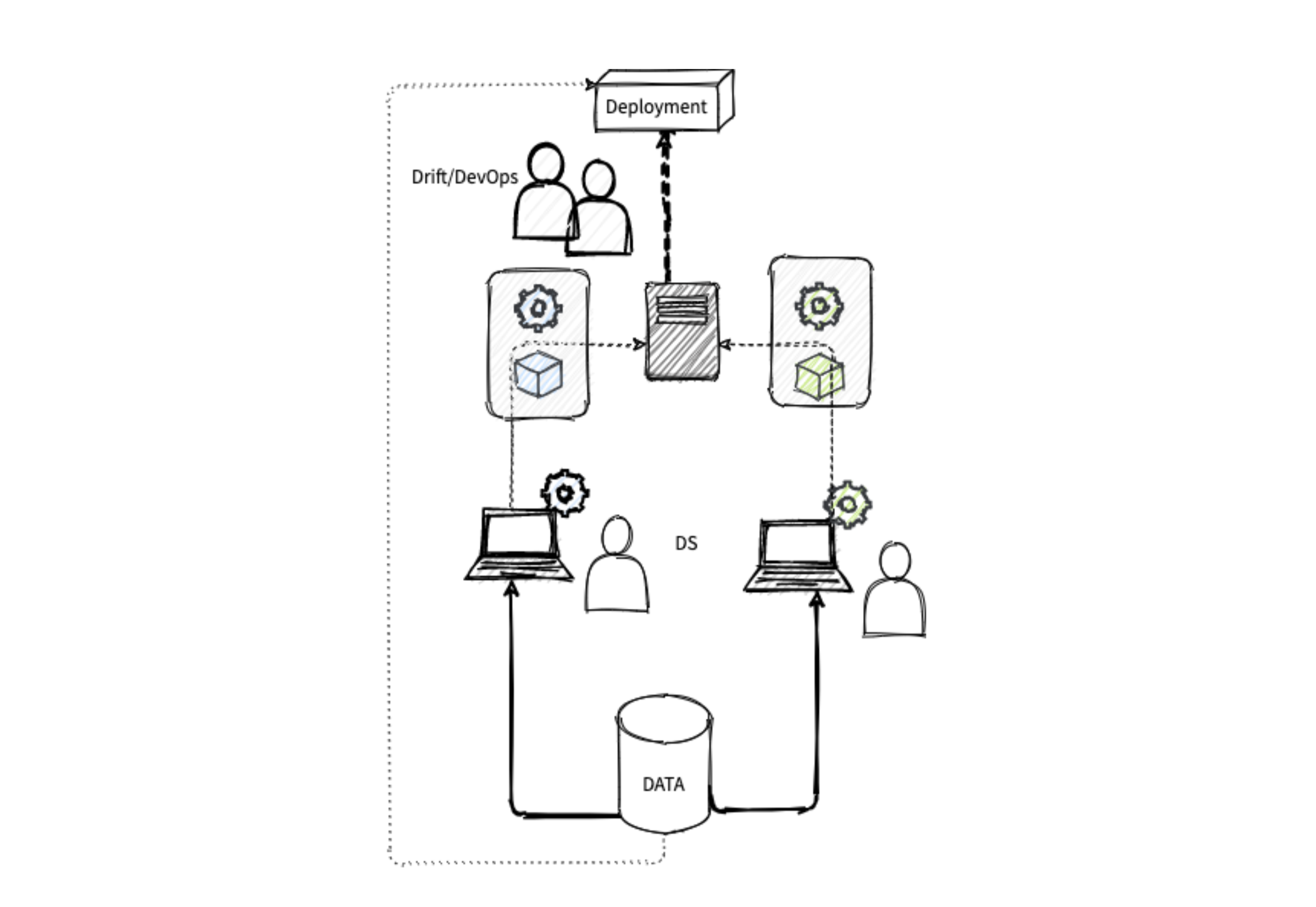

Det som sendes videre etter modellering er en ferdigtrent modell, en datapipeline og normalt en innpakning av miljøet, som en Conda-fil eller lignende. Dette i seg selv gir ofte utfordringer, og krever flere manuelle steg.
Men et større problem, er hva som ikke sendes videre. For selv om en gjerne har et system for versjonskontroll for selve ML-koden, er det ingen god måte å logge hvilke eksperimenter og eksplorativ analyse som ligger til grunn for valgene som tas. Eller hvilken tuning eller sampling som ble gjort i det modell- eller parametere ble valgt.
En annen utfordring er versjonering av modellene, eller livssyklushåndtering som mange foretrekker å kalle det innen ML. Uten et sentralt register, vil både DS og drift med tiden få utfordringer med å holde oversikt og logge hvilke modeller som opererer i hvilke miljø til enhver tid. Det går sannsynligvis greit en stund – men skalerer dårlig.
Problemene stopper heller ikke her. Det at verken monitorering, testing, utrulling eller modellanalyse er en integrert del av arbeidsflyten, gjør systemet sårbart. De fleste setter opp deler av dette, men det skjer ofte i egne løp, som gjør det vanskelig å ta i bruk systematisk.
En annen utfordring er at modelltreningen begrenses av DS-teamets egen hardware, som gjør det vanskelig og kostbart å skalere.
Men det aller viktigste problemet er at linken fra datasettet som ble brukt i trening til den ferdige modellen sannsynligvis forsvunner på veien, med mindre man har et uvanlig godt system for dataversjonskontroll og logging.
Hva bør en egentlig kreve av ML-systemet?
Hvordan går man så i gang for å forbedre analyseflyten? Vi tar utgangspunktet i hva man bør kreve og foreslår konseptuelle løsninger.
Modellregister med livssyklushåndtering
Det som ofte smerter tidlig etter at man har kommet skikkelig gang med å ta i bruk ML, er å holde styr på modeller og modellversjoner. Behovet for et modellregister kan gjøre seg gjeldende allerede etter andre modell eller modellversjon er satt i drift.
Ideelt sett henger modellregisteret sammen med versjonskontrollsystemet, og utrulling trigges ved kode og en godkjenningsprosess. Modellene bør enkelt kunne arkiveres i det de erstattes eller skal utfases av andre grunner.
Med et modellregister på plass har man løst en del av de store utfordringene. DS har ett sted å forholde seg til for modeller som er satt i drift, og kan henvende seg dit, for eksempel for å vurdere hvor godt modellene har gjort det for nye data. Drift kan på sin side konsentrere seg om å sette opp faste prosedyrer for å rulle ut modeller basert på registeret, i stedet for manuelle prosedyrer.
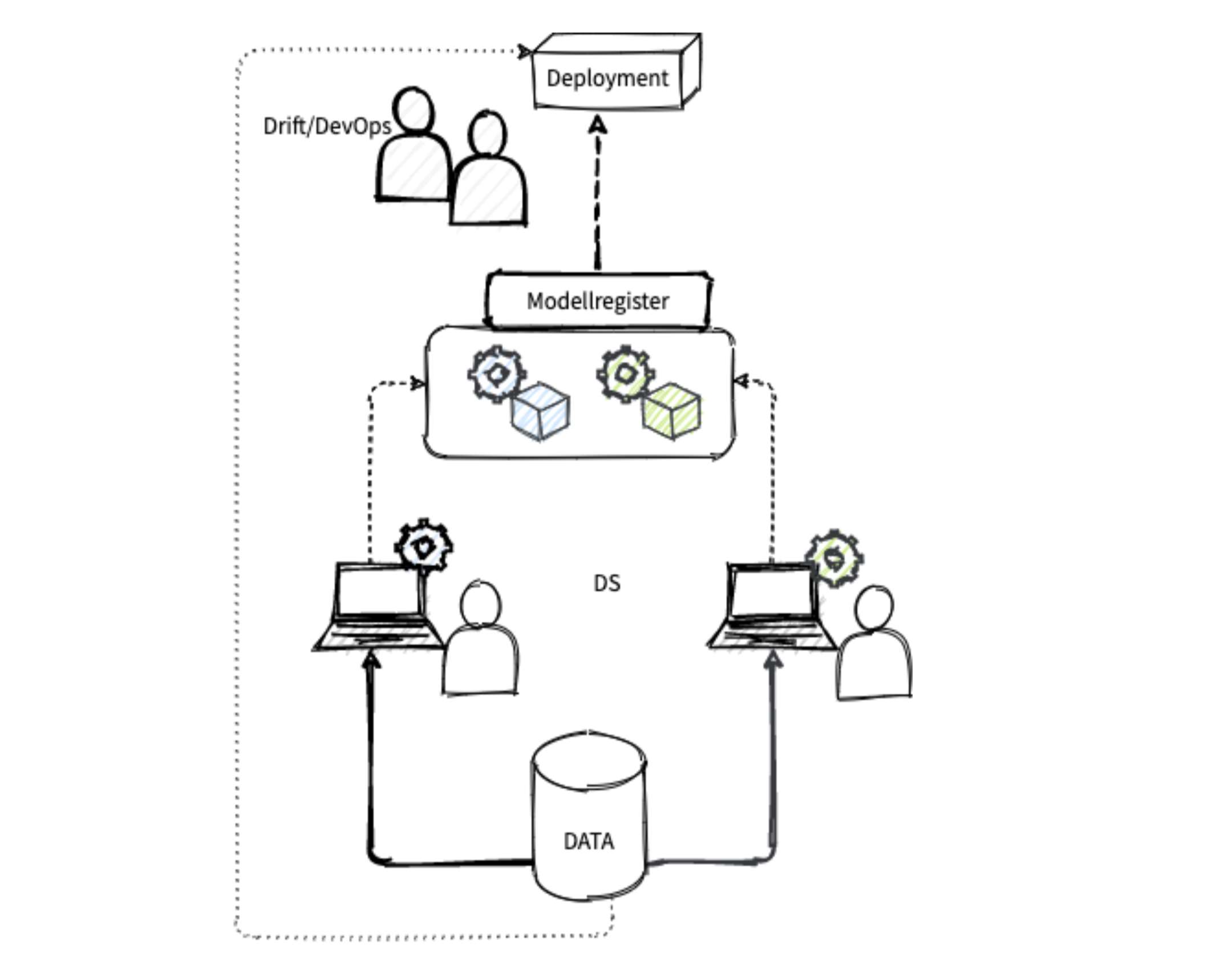

Det finnes gode og stadig mer modne rammeverk med både grafiske grensesnitt og gode løsninger for modellregister, som for eksempel MLflow og Kubeflow. Førstnevnte er spesielt godt tilpasset Spark, sistnevnte Kubernetes, og begge har åpen kildekode. Det er noe overlapp, men i visse tilfeller vil det være gunstig å bruke delelementer fra begge. I vårt enkle eksempel, mot slutten av denne artikkelen, har vi kun tegnet inn MLflow.
Skalerbarhet og valgfrihet
Dersom en har store data eller forventer å få det i fremtiden, kjører mange eller tunge modeller, eller retrener modeller ofte, er det viktig å tenke på maskinell skalerbarhet. I stedet for forhåndsdefinerte og hardwarebegrensede ressurser, kan man for eksempel velge et skybasert miljø med mulighet til å enkelt skalere opp og ut.
Muligheten til å skalere handler ikke nødvendigvis bare om å skalere opp. Ved å dra skyressurser opp og ned, for eksempel etter daglig eller ukentlig modelltrening, slipper man å betale for ressurser som står på tomgang.
De data som i dag er aktuelle å benytte, er kanskje bare en liten delmengde av de data en vil dra nytte av om noen år. Vi tror det vil være lurt å ha et fleksibelt system som kan håndtere stadig større krav.
Spark er det ledende rammeverket for fleksibel stordataprosessering, og tas ofte i bruk for å håndtere flyten av store datamengder. Men også etter at datasettene er prossessert, er det gode grunner til å se på muligheten for å dra nytte av Spark. For eksempel til parallellisering ved parametertuning eller kryssvalidering.
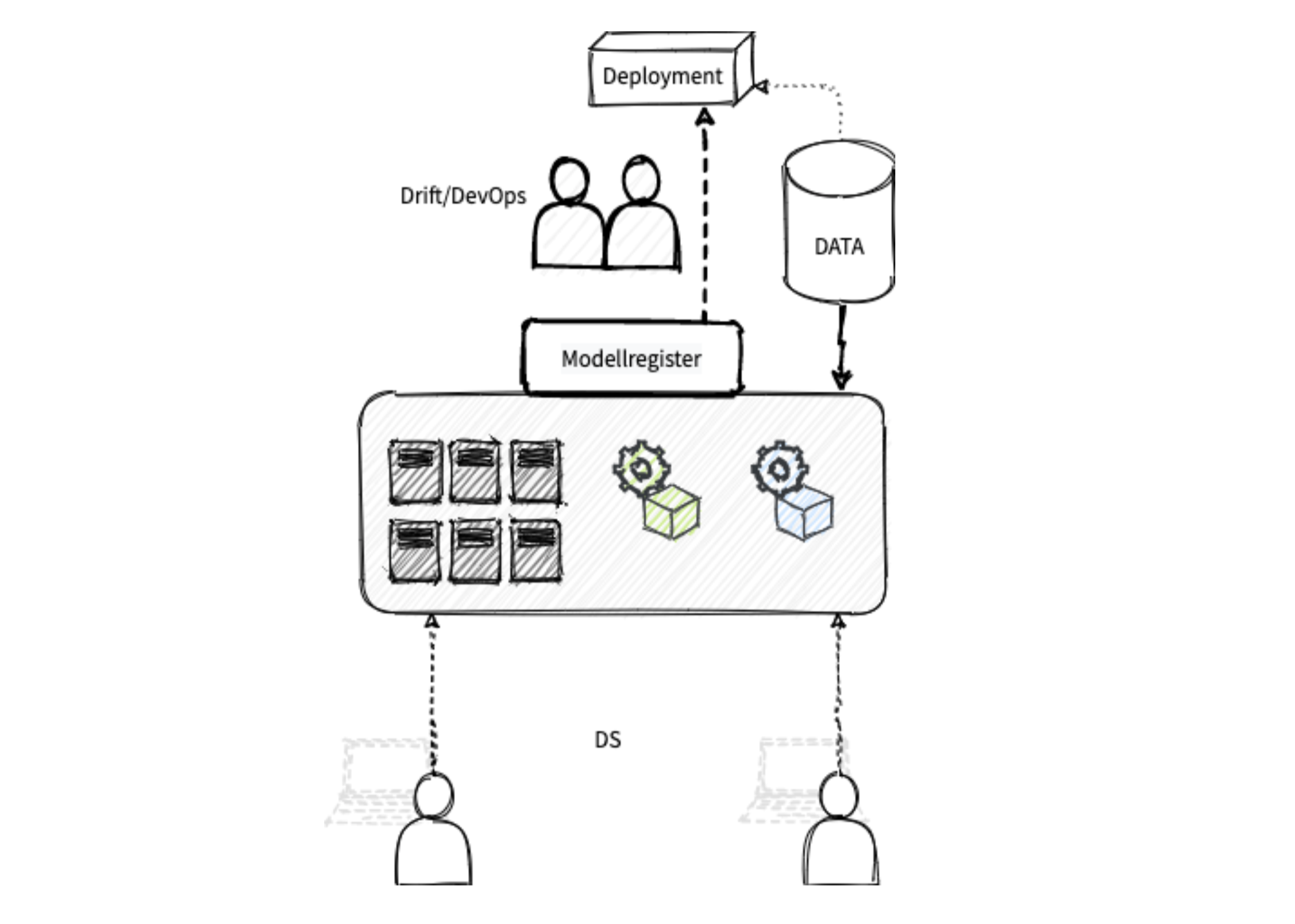

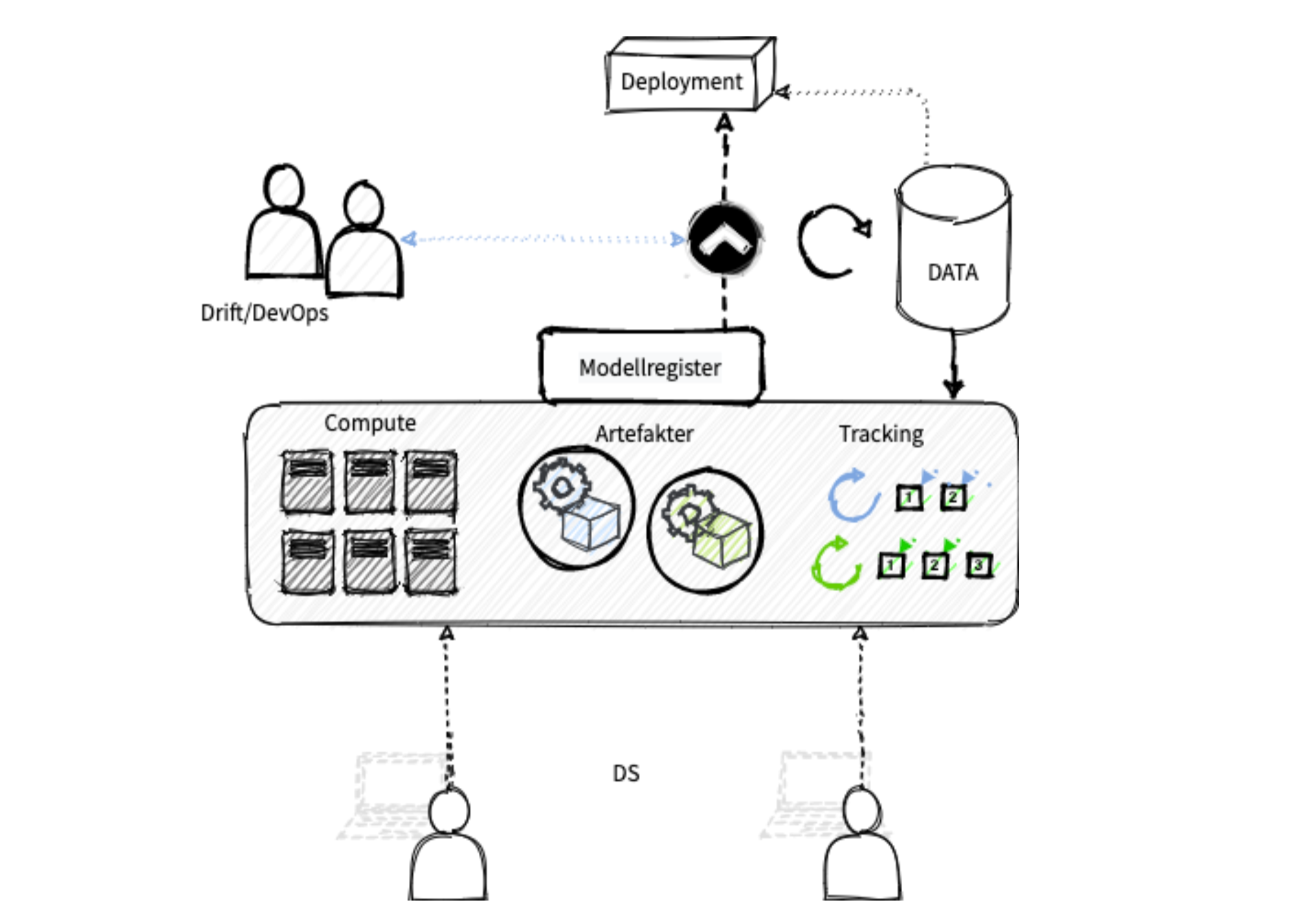
Bildet over demonstrerer en arkitektur vi har erfart at fungerer godt. DS-teamets egne laptoper er i essensen redusert til monitorer for å benytte ett eller flere delte cluster, som enkelt kan skaleres etter behov. En hyggelig bieffekt er at det også blir enklere å samarbeide i ett og samme miljø uten å synkronisere biblioteker lokalt.
Fellesmiljøet DS-teamet jobber i bør være rigget slik at man har like stor valgfrihet som ved lokal utvikling. Som et minimum bør det være støtte for både R og Python, de mest populære språkene innen maskinlæring. Det bør også være enkelt å ta i bruk og holde styr på et fritt utvalg biblioteker og versjoner.
Sporbarhet og reproduserbarhet
Neste krav på listen er sporbarhet og reproduserbarhet. For selv med et velfungerende modellregister som viser hva som har vært i hvilken tilstand når, og et skymiljø som motor for treningen, er det vanskelig å spore seg tilbake til de antagelser og valg som ble gjort på veien til den endelige modellen. En bør derfor innføre systemer for å spore hvert eneste eksperiment som kjøres. Det er flere grunner til dette.
For det første: Compliance. Det er strenge krav til hvordan en kan bruke persondata til å trene modeller. En bør derfor være 100% trygg på hvordan man egentlig har tatt valgene som har gjort. Kan det tenkes at en implisitt har modellert for eksempel etnisk bakgrunn? Dette bør en ha stålkontroll på og mulighet til å gjennomgå. Ved automatiserte beslutninger basert på ML vil det kunne stilles krav til å vite hva som inngikk i beslutningsgrunnlaget. Uten et godt system for sporing er dette praktisk talt umulig.
For det andre: Datalekkasje. Ved å for eksempel utelate datapreprossessering fra modellseleksjonsrutinen er det svært enkelt at en overtilpasser modellen til treningsdatasettet. Uten sporing i ethvert eksperiment, er det svært vanskelig å kvalitetssikre at det ikke har blitt gjort noen uheldige valg på veien til modellen.
For det tredje: Handover og kredibilitet. I noen tilfeller, for eksempel for en helt ny modelleringsoppgave, må det tas en avgjørelse på høyere nivå for å faktisk ta modellen i bruk. Dette vil ofte stille høyere krav til forståelse for de bakenforliggende prosessen. Her kan en god sporingsmekanisme bidra til økt transparens og dermed økt kredibilitet som gjør godkjenningsprosessen enklere.
En mulig måte å løse sporing på rent teknisk er ved et strengt regime for kode- og dataversjonering, men da vil det likevel være vanskelig å holde styr på alle kjøringer. Igjen kan det være fornuftig å ta i bruk et MLOps-rammeverk, som de vi allerede har nevnt. Eventuelt kan en ta i bruk integrerte verktøy som tilbys av noen av de store ML-plattformene, som Amazon Sagemaker.
Med full kontroll på eksperimentene som kjøres kan vi langt på vei påstå sporbarhet. Neste punkt på listen er reproduserbarhet. Her finnes flere muligheter.
En metode er å containerisere koden for plattformuavhengig utrulling. En annen mulighet er å holde seg til et standard pakkeformat som gjør det enkelt å ta i bruk koden uavhengig av modellens format. I figuren under har vi demonstrert dette ved å samle kode og miljø som ensartede pakker, hvor en ideelt sett kun spesifiserer datasignaturen som sendes inn til modellen ved bruk, altså et dataschema.

Men et modellregister som peker på pent pakkede artefakter, en link til eksperimentene som genererte artefaktene, og en sporbar flyt tilbake til datasettene som ligger til grunn, er vi nesten fornøyd. Det siste kravet vi ønsker å diskutere handler om måten modellene fra registeret tas i bruk.
Modellservering og integrasjoner
Vi tror det er fornuftig å la DS selv ta større eierskap til selve serveringen av modellene. Der drift tidligere har vært avgjørende for å få modeller i drift, vil et godt CI/CD-oppsett gi DS selv mulighet til å ta nye eller oppdaterte modeller i bruk, eller fjerne eksisterende modeller eller versjoner. Drift blir en uvurderlig støttespiller som hjelper til med å implementere gode verktøy for automatisert testing, monitorering og lignende, men ikke for hver eneste utrulling.
Med en integrert utrullingspipeline som trigges av endringer i modellregisteret, ligger alt til rette for smidig utvikling, også for DS-teamet. Veien fra modellering til produksjon blir langt kortere, og krever mye mindre manuell innsats.

Et løsningsforslag i praksis
La oss nå anta at vi ønsker et system som beskrevet over. Hvordan kan vi løse dette i praksis?
Figuren under beskriver en enkel måte man kan sette opp en slik flyt hos en skyleverandør, i dette eksempelet Azure. Blokken til venstre beskriver data som kommer inn i analysemiljøet. Ideelt sett kommer data som Delta Parquet for enkel og effektiv versjonering. Det sikrer at det blir enklere å reprodusere modeller. Det gjør det også lett å sette opp strømmende jobber som reagerer på nye data. Sjekk gjerne artikkelen om Delta Lake for et dypdykk.
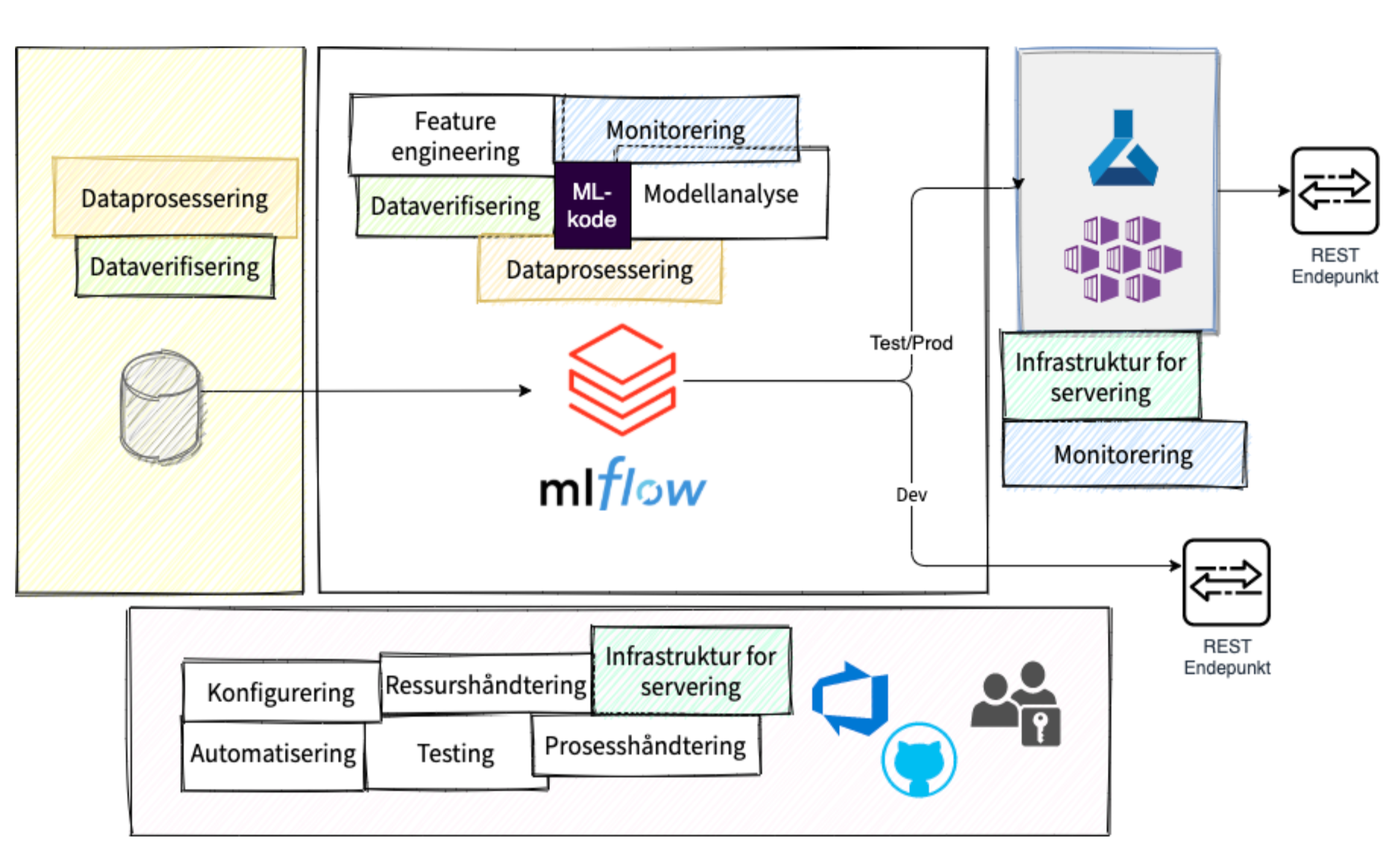

I bunn finner vi infrastruktur, ressurshåndtering, testing, konfigurering og automatisering. Dette kan for eksempel styres gjennom vanlige versjonskontrollsystem og CI/CD-pipelines. Her har vi foreslått GitHub og Azure Devops. Sistnevnte vil naturligvis henge sammen med hvilken skyleverandør en benytter.
I midten finner vi komponentene som er avgjørende for selve ML-koden. Databricks foreslås fordi det er enkelt å ta i bruk, gir stor frihet, enkelt kan skaleres, er tilgjengelig hos alle større skyleverandører og er godt integrert med både Delta Lake og MLflow.
MLflow gir løsningene vi trenger for sporbarhet, reproduserbarhet og livssyklushåndtering, og til en viss grad også servering, dog ikke for kritiske applikasjoner. Derfor tar vi også i bruk Kubernetes Services, for servering med høye krav til throughput.
Dette er kun et eksempel. Vi har god erfaring med denne flyten, men tror det kan være fornuftig å holde seg innenfor rammene til eksisterende skyleverandør.
Kom i gang
ML-flyten vi har skissert vil gi en langt kortere vei fra idé og eksperimentering til faktisk å ta i bruk modellene. Det gir etter kort tid lavere vedlikeholds- og skaleringskostnader.
En annen fordel med oppsettet er at det blir enklere å onboarde nye team-medlemmer, fordi all kode og modellering er versjonert, og infrastrukturen allerede er satt opp med standardiserte løp.
At kommunikasjonen DS-teamet mellom i større grad foregår gjennom kode og analyseflyt, kan også gjøre det enklere å restrukturere. Kanskje kan en Data Scientist heller sitte nærmere et ledd i virksomheten, for økt påvirkning og bedre samspill med domeneekspertene – samtidig som han har en god arena for samarbeid gjennom en sentral analyseflyt.
Vil dere ha hjelp til å sette opp et godt skybasert miljø for maskinlæring? Ta gjerne kontakt, så ser vi om vi kan få til noe bra sammen.